Kaggle が提供している jupyter notebook で training や prediction 実行する際に、そのままの設定だとものすごい時間がかかりました。
待っていても、少しずつ進んで行くはいいものの気がついていたらセッションがタイムアウトされてしまったり・・・。
こんな時どうするのかな?というところを見てみるとAccelleratorを変更すると良いらしい
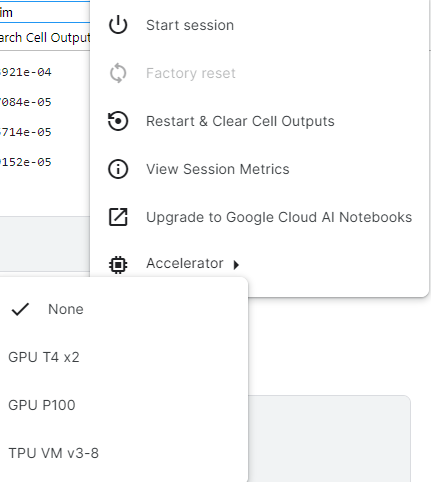
なるほど、これか。
選択肢としては
- None (CPU)
- GPU T4x2
- GPU P100
- TPU VM v3-8
とある。それぞれどういう時に使うといいとかどっかに書いてないかな?と思い、一旦それぞれに関して調べてみた
まとめ
最初に簡単にまとめておく
| 名前 | モデル | アーキテクチャ | Core | Memory | その他 | 用途 |
| GPU T4x2 | NVIDIA GPU model from the Tesla series. | Turing | 2,560 CUDA cores | 16 GB of GDDR6 memory | T4 GPUs include Tensor Cores, which can accelerate certain deep learning operations, particularly when working with mixed-precision training | |
| GPU P100 | NVIDIA GPU model from the Tesla series. | Pascal | 3,584 CUDA cores | 16 GB or 12 GB of HBM2 memory. | In general, GPU P100 is considered more powerful than GPU T4, primarily due to the higher number of CUDA cores and better memory bandwidth. However, the actual performance depends on the specific workload you’re running. | |
| TPU VM v3–8 | Google TPU v3 | 8 Core |
GPUとTPUは違いすぎて比較表がうまく作れなかった。。。
GPU T4x2
明確な公式文書は見つけられなかったが、フォーラムにはP100と比較したコメントが出ていた
What is the difference between ‘GPU T4 x2’ and ‘GPU P100’ in the notebook? | Kaggle
GPU Model: T4 is an NVIDIA GPU model from the Tesla series.
Architecture: T4 is based on the Turing architecture.
CUDA Cores: T4 has 2,560 CUDA cores.
Memory: T4 typically has 16 GB of GDDR6 memory.
Performance: T4 offers good performance for a range of tasks, including machine learning, deep learning, and general GPU-accelerated computations.
Tensor Cores: T4 GPUs include Tensor Cores, which can accelerate certain deep learning operations, particularly when working with mixed-precision training.
GPU P100
GPU P100 に関しての公式文書としては下記を見つけた
Efficient GPU Usage Tips and Tricks
Kaggleは、NVIDIA TESLA P100 GPUへの無料アクセスを提供します。これらの GPU はディープ ラーニング モデルのトレーニングに役立ちますが、他のほとんどのワークフローを高速化することはありません (つまり、pandas や scikit-learn などのライブラリは GPU へのアクセスの恩恵を受けません)。
ふむ・・・。
ただ、Acceleratorの適用がセッション単位なんじゃないかな。
最終的に notebook でトレーニングするにしてもその前段となるpandas等の処理部分を省くことはできないし。
notebookを分割して前処理部分とトレーニング部分を分ければいいのかな?
GPU の週あたりのクォータ制限まで使用できます。クォータは毎週リセットされ、需要とリソースに応じて 30 時間以上になる場合があります
このあたりは注意が必要ですね。
一回あたりの実行時間がどれくらいかにもよるし、週に30時間であれば十分な気がするけれど。。。
TPU VM V3-8
TPUそのものが何かに関してはこちらの記事が参考になった
【AIメモ】GoogleのTPUがすごい (zenn.dev)
TPUに関してはKaggle内にも情報が乗っていた
Tensor Processing Units (TPUs)
こちらを読み進めていくと、TPUの性能をちゃんと活かすためには、バッチサイズだとかを適切にする必要があるそうな。
バッチ サイズが大きいほど、TPU はトレーニング データをより高速に処理します。これは、トレーニング バッチが大きいほど “トレーニング作業” が多くなり、モデルをより早く目的の精度に到達できる場合にのみ役立ちます。そのため、経験則では、バッチサイズに応じて学習率を上げることも必要です。
ただ、ちょっと下の方に気になることが。。。
特定の種類のコードのみのコンペティションには技術的な制限があるため、コンペティションのルールで明確にされているように、TPU で実行されるノートブックの提出をサポートすることはできません。しかし、だからといって、TPU を使用してモデルをトレーニングできないわけではありません。
この制限の回避策は、TPU を使用する別のノートブックでモデルのトレーニングを実行し、結果のモデルを保存することです。その後、そのモデルを送信に使用するノートブックに読み込み、GPU を使用して推論を実行し、予測を生成できます。
というわけで、提出用のnotebookに関してはTPUなど特定の技術に依存したものはNG。ただ、モデルを作るスピードは早いので、別のnotebookでモデルを作った上で、そのモデルを利用するのはOKということらしい。
色々ありますねぇ