iOSアプリにはAppClipという仕組みが導入されていて、アプリをインストールすることなく簡易にアプリを体験することができる。
AppClip概要
https://developer.apple.com/jp/app-clips
AppClip(開発者向け)
https://developer.apple.com/jp/documentation/app_clips
AppClipは上記ページにも書かれているが、NFCやQRコードなどを読み込むことでカード状のハーフモーダルが立ち上がる。
このハーフモーダルから起動されたアプリは、本来のフルサイズのアプリではなく、一部の機能のみを有効にしたコンパクトなものなので、手軽に利用が可能。
さらに、基本的にはログイン不要で利用することができるということを想定されている。
フルサイズのアプリがインストールされていれば、そちらが起動するのでその場合は本来のアプリの機能すべてを利用可能になるという寸法だ。
AppStoreConnectの設定
このAppClipだが、機能の作り込みに関してはもちろんアプリ開発が必要になるのだけれど、カードを表示する部分に関してはAppStoreConnect上の設定となる。
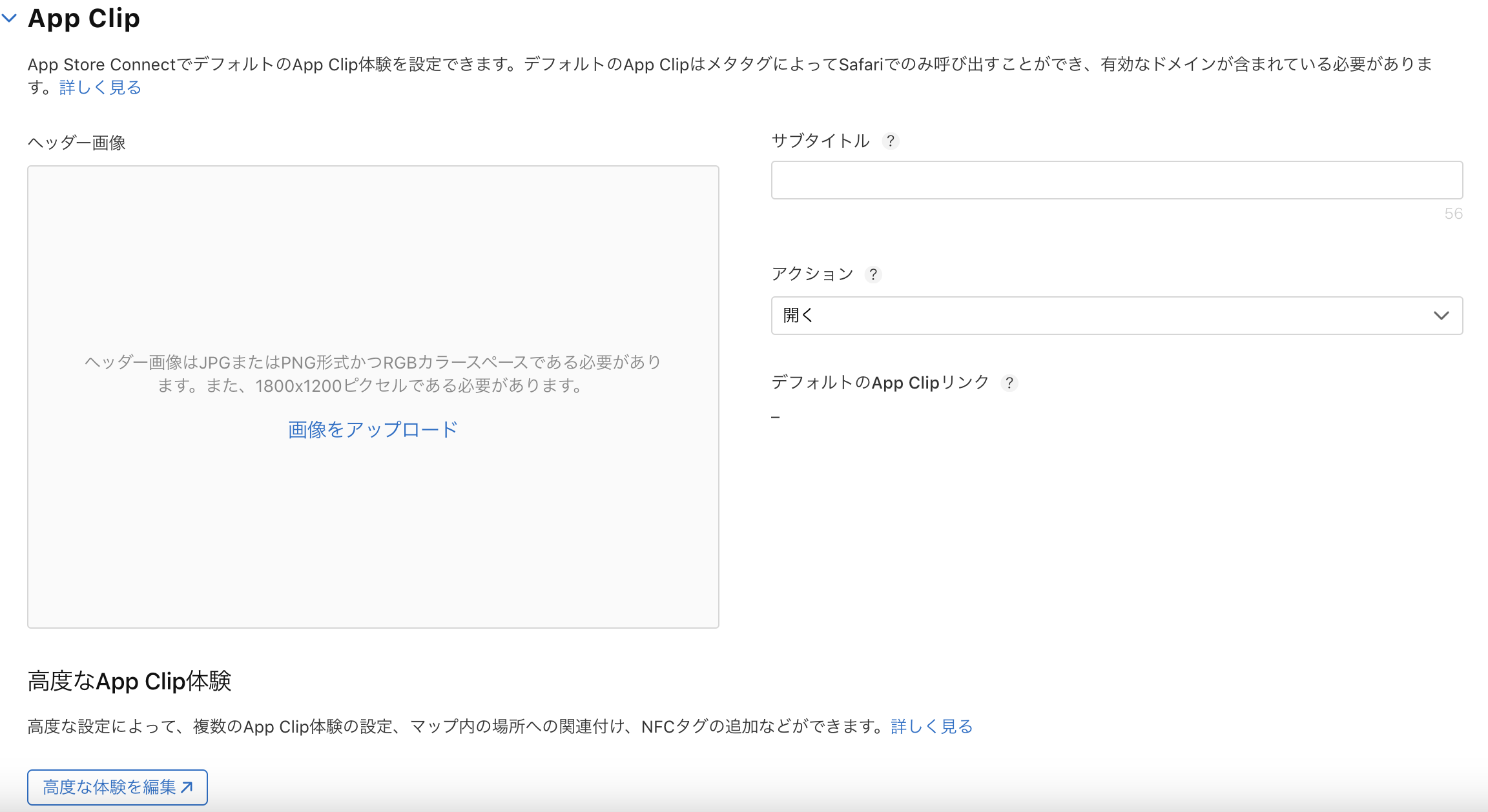
AppClipのカードに関する設定はAppStoreConnectのアプリ情報入力ページ、中段くらいに用意されている。
カードに関しては1800×1200ピクセルというサイズ指定がされており、AppClipが一つである場合はメインページ上で設定することになるが、複数のAppClipを用いる場合は「高度な体験を編集」というリンクに従って専用ページで情報を入力する必要がある。
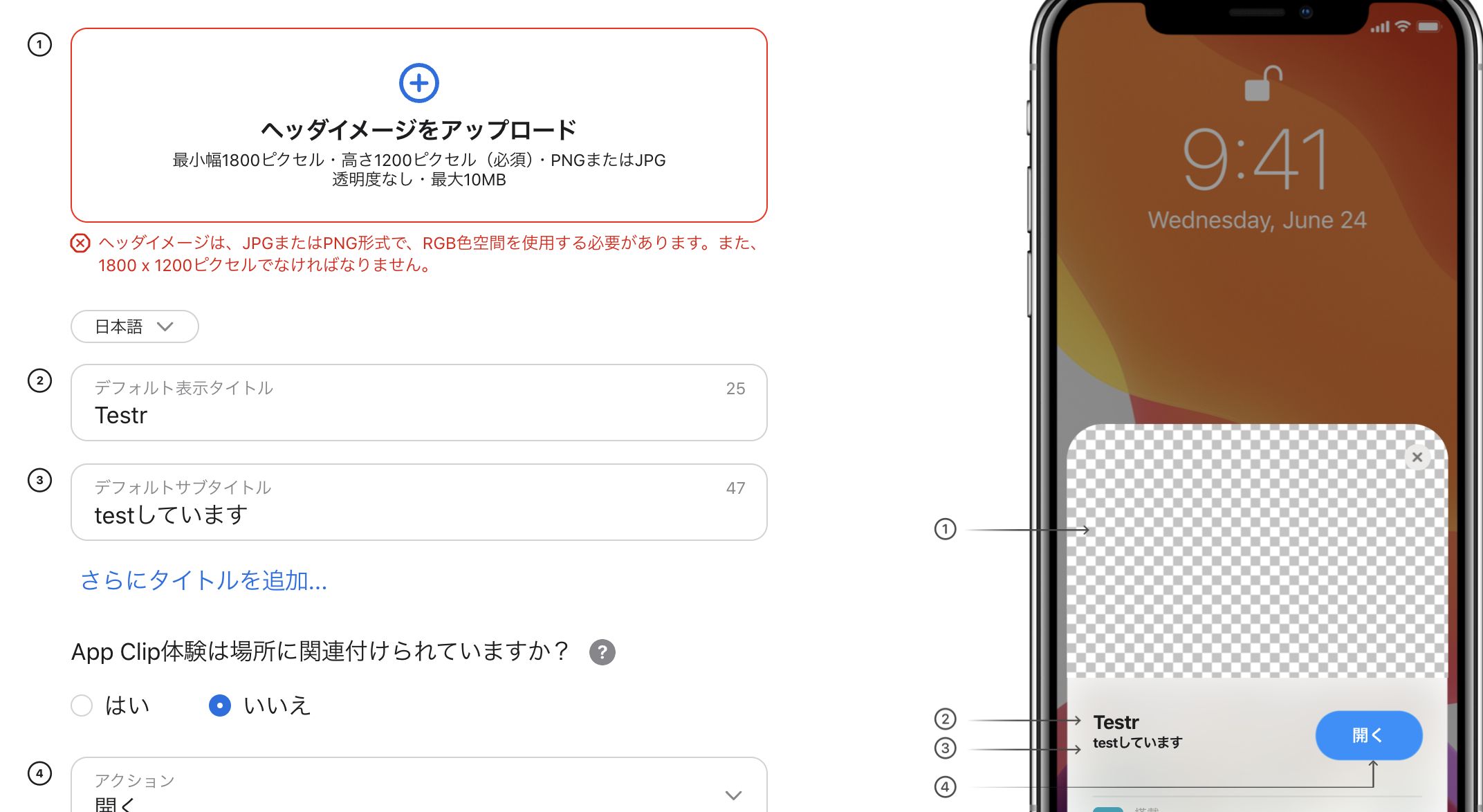
体験を編集する際に必要となる情報としては、カードの画像、表示タイトル、サブタイトルと、AppClipを読み込んだ際の動きに関する設定だ。
これ以外に、呼び出し用のURLやAppClipのバンドルIDなどを指定することになる。
カードの設定変更に関する注意点
AppClipの起動によって呼び出されるアプリケーションは、当然のことながらStore公開のための審査を通過する必要があるのだけれど、AppClipに関する設定はなぜか審査と無関係に反映されているように見える(2024-09現在)。
特に、AppStoreConnect設定では、現在公開中のバージョンと準備中のバージョンがあったとして、その両方からリンクされている「高度な体験を編集」画面は同じものになっているように見える。
逆を言うと、このバージョンまではこちらのカードを利用。
このバージョン以降はこちらのカードを利用と言ったことをしようとすると、リリース後に設定を変えるなどの一手間がかかるような作りになっている。
これに関しては、やはりちょっとおかしい気もするので修正が入るのではないかと思っている。
そのため、画像の差し替えなどは比較的簡単に行うことができるように見える。
ただ、これはキャッシュが効いているのかどうかわからないが、新しい画像が読み込まれるまで少し時間がかかる可能性がある。
ちょこちょこ起こる不具合
上記のようなAppStoreConnectの動きは正直言ってバグなんじゃないかと思っている。
また、最近直ったようだが、StoreConnect上のカード画像を変更しても反映されなかった不具合もフォーラム上で散見される。
ぶっちゃけAppClipどこまで使われているんだろうなー。。ってことを思うと、近い将来に「この機能無くなるんじゃないか?」と不安に駆られる面もある。
色々と新しい体験を出してくれるのはAppleのいいところでもあるんだけど、それらを無邪気に組み込んで大丈夫なんだろうか?に関しては一抹の不安が残りますよね

