これまで、ブラウザはBraveを利用してきましたが、Microsoft Edgeがここのところ気になる機能を出しているので移行を検討中です。
SplitView
1つ目の気になる機能としてはSplitViewです
今、モニタとしては4年前に購入した29インチのウルトラワイドディスプレイを使用しています
ウルトラワイドなので、ここにブラウザを半々に表示させて作業をしています。
左のブラウザでXを表示させながら右のブラウザでネットを見ていたり、X上で投稿された記事を右のブラウザにアドレスをコピペして表示させるなどですね。
Edgeのスプリットビューは、一つのタブを分割することができるようになります。
ツールバーの上記アイコンを押下することで画面が分割され、
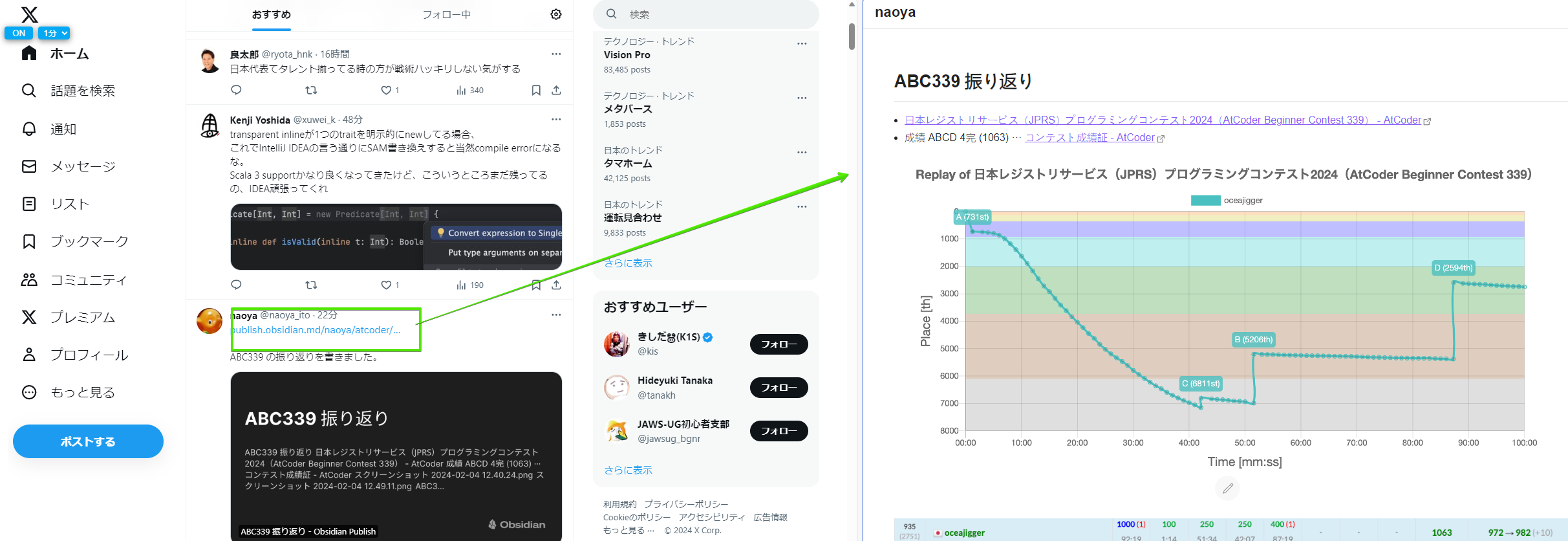
左側のページ上にあるリンクをクリックすると、右側のビューに表示されるような感じ。
どちらのビューにデフォルトとして表示させるのかや、左右の切り替えはビュー右上にある3点リーダーをクリックして表示されるメニューで指定することができる
使ってみてよかったところと注意点
ウィンドウ自体を2つ配置すること自体は、これまで不便に感じたことはそれほどなかった。
ただ、この仕組みを使い始めるとなかなか便利である。
表示するページによっては、画面全体で見たいときもあればそうでなくても問題ないこともある。
タブごとにSplitするかどうかを選択することができ、更に分割位置も調整することができるのでその比率をいい感じにすることができる。
クリックした際に自動的に別ビューに表示されるのでコンテキストメニューから「別のタブで開く」を選択する必要性はない。
注意しないといけないのは、別のリンクをクリックするとビューの内容が更新されてしまう。
そのため、次々と新しいタブを開いていくとい運用は向かずに、一つ一つ読み終えてからリンクを開く必要性が生じてしまっている
まぁ、落ち着いて読んで行けよと言われればそのとおりなので、実際に問題になるのかは使ってみて考えることにする
コレクション
気になったものを保存する先として、お気に入り以外にコレクションと言う機能が追加されている
ツールバーの上記アイコンを押下することでコレクションを表示させることができる。
コレクションは、Webページ全体だけでなく、その中の画像や文字列のみを追加することができるので、ちょっとしたスクラップブックのようなイメージ。
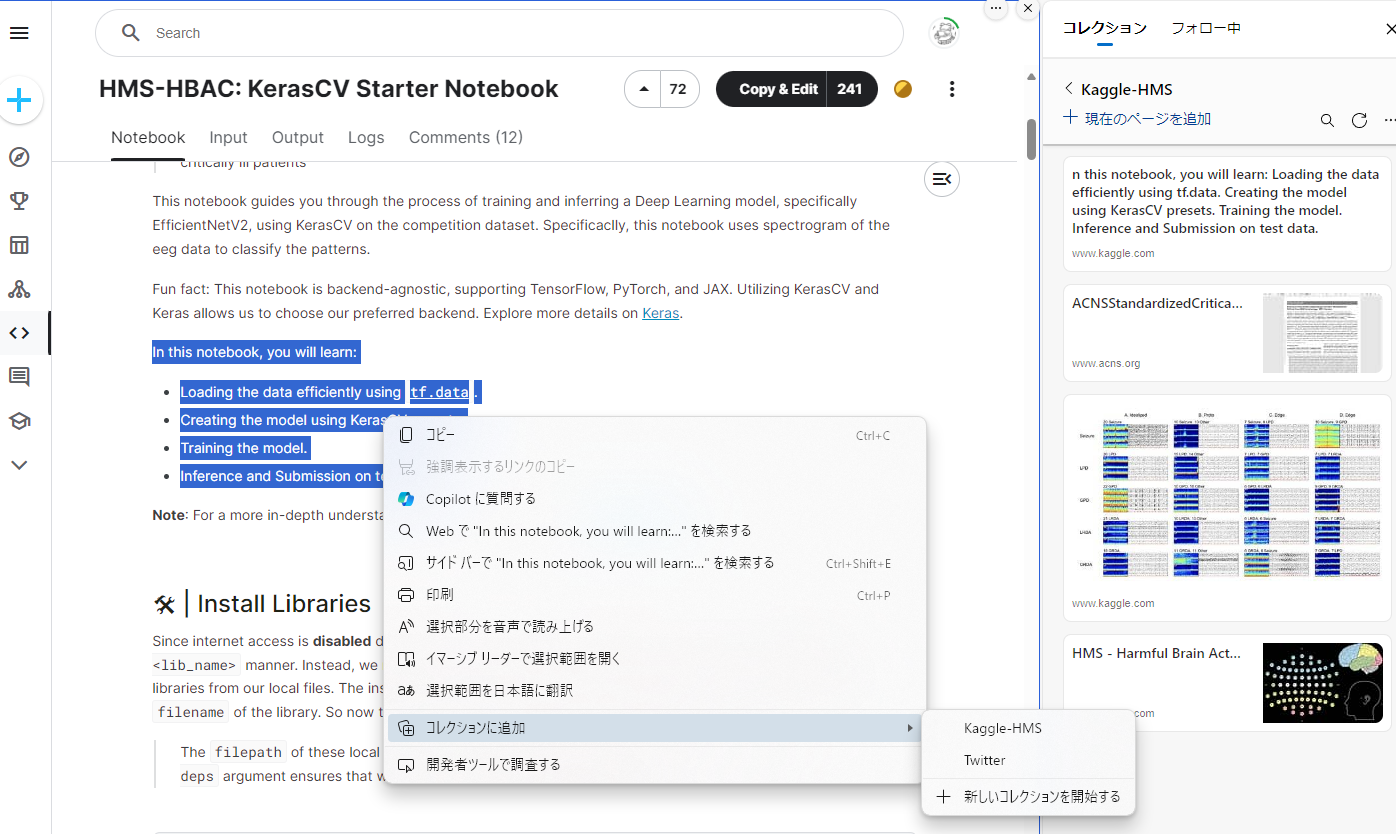
追加したコンテンツは画像であれば画像、文字であれば文字がコレクションに追加されていき、クリックするとその元となったページが表示される。
使ってみてよかったところと注意点
何かしらテーマを持って調べ物をしている際に、面白いなって思ったことをメモ代わりに追加しておけるので、後で読もうかな?という感じでタブを開きっぱなしにするといったことを防ぐことができるかもしれない。
カテゴリごとにコレクションを作って、面白かった記事や文言を抜き出してコレクションに追加していけば、情報収集や整理が楽になりそうな気がする。
追加したコレクションにはメモを残すこともできる
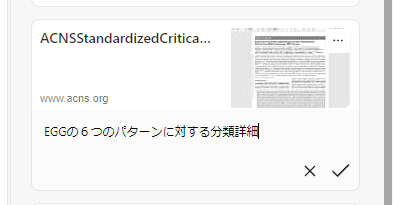
メモを残すことで、対象をなぜコレクションに追加したのかを後から見返した際にすぐに気づくことができるようになる。
一方で、コレクションに追加したものをクリックすると新しいタブで表示されてしまう。
画像をクリックした際には画像を拡大表示する、テキストをクリックした際にはテキストを選択可能にするといったほうが個人的にはいいように感じるけど、そのあたりは情報が更新されている可能性だとか、著作権的になのか、リンクと言う形を取ったほうが安全とかそういうことがあるのかもしれない。
Microsoft Rewards
これまで、Braveを使ってきた一つの理由がBraveのReward機能だ。
Braveは広告のブロックに力を入れていて、Webページ上の広告を自動的に非表示にしてしまう。
一方で、Brave自身が定期的に広告を出すような仕組みを入れている。
このBraveがだす広告による収益は、Braveのユーザに仮想通貨(BAT)として還元される。
つまり、Braveを利用しているだけで仮想通貨を取得することができるのだ
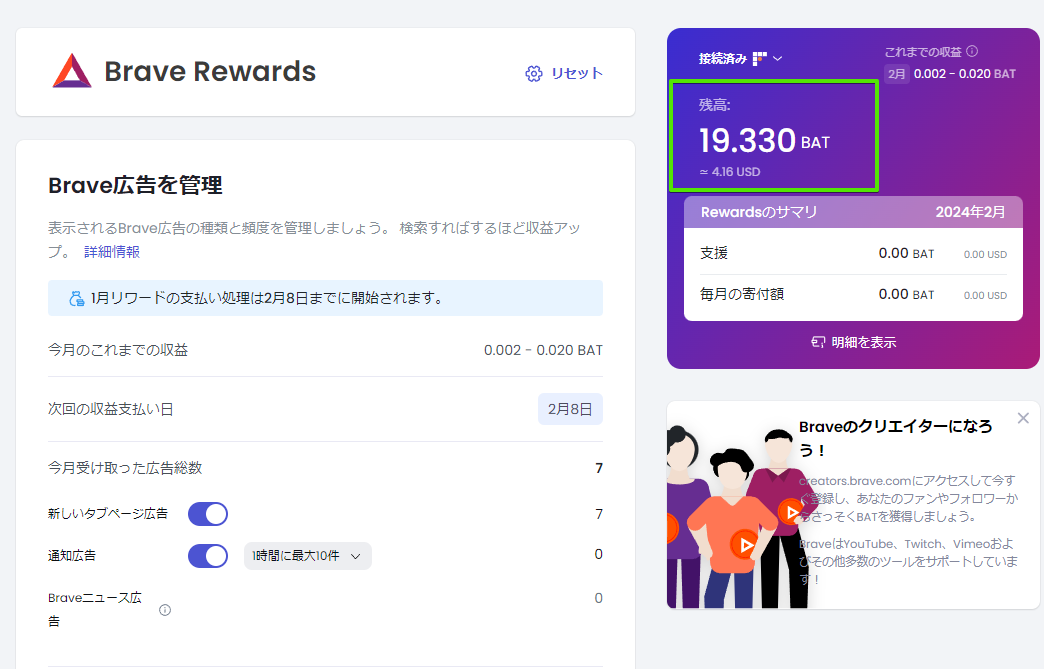
これらに関しては、bitFlyerなど仮想通貨取引所でアカウント作成して連携しておく必要はあります。
さて、これまでの履歴を見てみると。。。
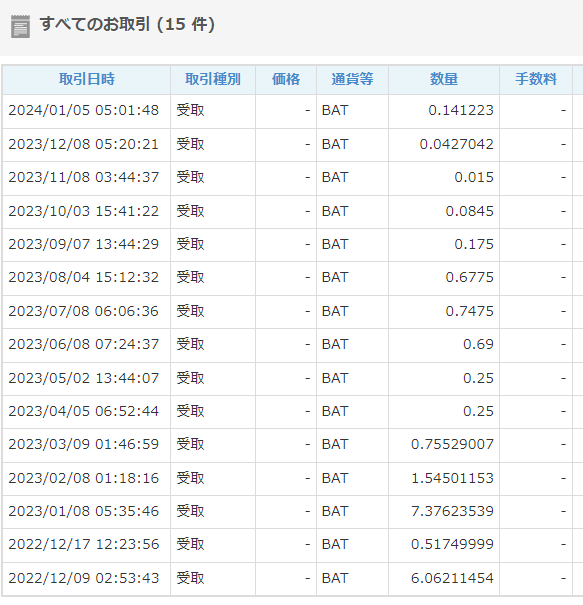
月によって、ものすごいばらつきがありますが、仮に、平均0.5BATとすると、2024/2/4現在

一ヶ月15円くらい・・・・?
うーん、別にこれで儲けようとか思ってはいないですが、これを理由に続けるかどうかはあまりに意味がないですね。
と思っていたら、Edgeにも Microsoft Rewards なるものが。
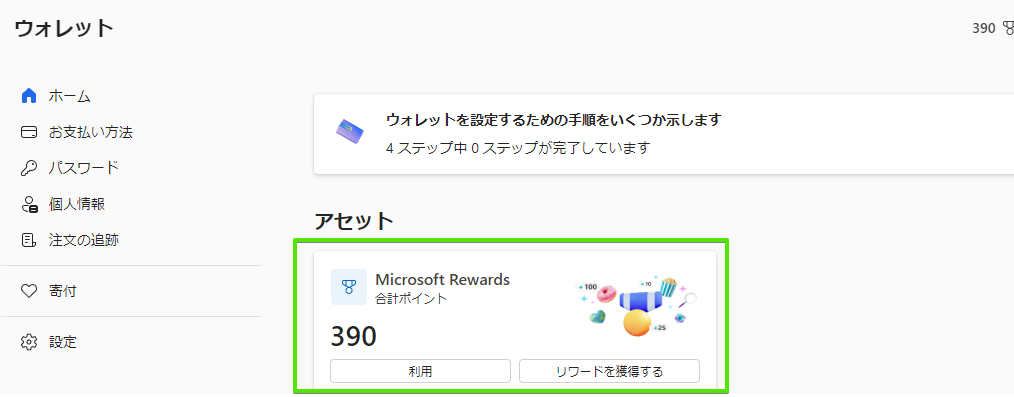
現在のRewadsポイントはウォレットを表示することで確認することができます。
Rewardsは、Bing使ったりしていると貯まるようで、ちょっとした日々の指定されたアクティビティをすることでも貯めることができる。
ためたRewadsはAmazonギフト券とかと交換することもできるようだが、そのために色々と頑張るのもちょっとバカバカしいので、これはあくまでオマケ機能と思っていたほうが良さそうだ。
しばらく使ってみて判断
まだ、本腰入れて移行するかは決めていないけれど、SplitViewで次々と表示させながら、気になったものをコレクションへ追加するという運用は、良さそうに思える。
XやGMailで届いたものを開いていったり、Kaggleのノートブックを集めていったりと、お気に入りでやってしまうには永続性がないものはコレクションに追加していき、必要がなくなった時点でコレクションごと削除、とか。
BingChatでGPTへの質問とかも気軽にできるようになっているので、しばらく使っていなかったけどEdgeの進化スピードは気づいたらすごいことになっているイメージ。
まだ埋もれた機能もあるだろうから、ちょっと一度しっかりと見てみると生産性がバク上がりするかもしれないな、と思った。