今年も残すところあと僅か
というところで、テッパンネタではありますが振り返りをしたいと思います。
マラソンに関して
昨年、比較的良いコンディションと自分では思っていた湘南国際マラソンで結果を出せずに新たな気持ちで取り組み始めた2025年でした。
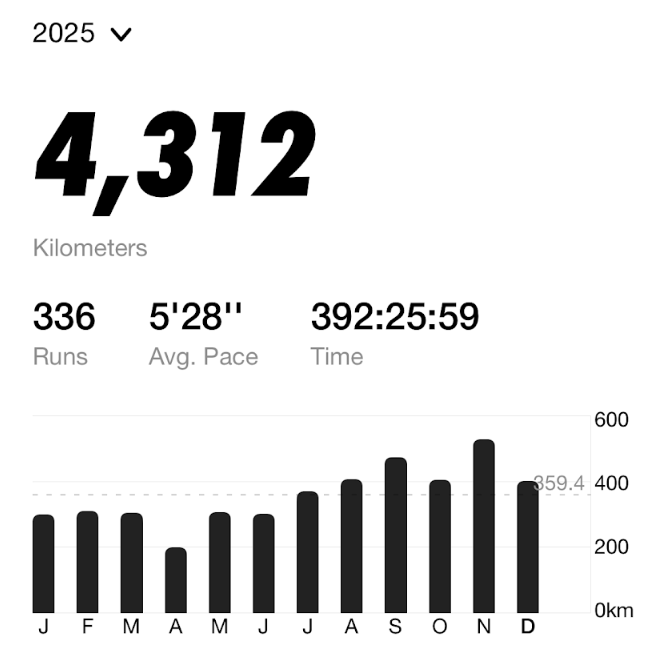
まず見てわかるのが月間走行距離がを格段に伸ばしました。
平均しても359km/月。8月以降に関しては400km/月を維持しています。
多少月によってのばらつきはあるものの、昨年までと比較すると倍に達する勢いです。
このあたりは月間ランナーズが主催しているランナーズ+(プラス)へ参加して色々なコーチの話を聞いている中で、しっかりと距離を踏んでいこうと考えた次第です。
夏でも朝晩走ることで、月間走行距離を伸ばしていきました。
そのかいもあり、水戸黄門漫遊マラソンでは初のサブ3.5。
かさま陶芸の里ハーフマラソンでは1時間半を切るという自己新を叩き出すことが出来ました。
特にかさまハーフで走ったペースはサブ3につながる一歩目となったのではないかと。
4:14/kmというペースは正直自分には遠い印象でしたが、全然手の届かない位置にはいないと自信を持つことが出来ました。
また、12月には50km、60kmとチャレンジ富士五湖に向けた超長距離を進めることが出来ています。
仕事の忙しさによって走る時間の確保が難しいところではありますが、この良い流れを維持できるようにしていきたいところです。
仕事に関して
昨年に会社がM&Aにより子会社化され、その関係もあって組織的な変更が続いた1年であったように思います。
直近では、オフィスも移転したことで環境も大きく変わりました。
環境が変わると言っても、それによる変動というのは誤差の範囲ではあるのですが、組織内のドタバタのほうが影響としては大きく感じました。
エンジニアをやっている以上、技術に対して向き合っていきたいところではあるけれど、いつになっても向き合わないと行けないのは人になります。
わかってはいるものの、これが非常に辛さが残る。
あまりにもバカバカしい所あり、転職も視野に入れました。
しかし、年齢的には50前のおっさん。しかも何かに秀でているわけではない。
いくら買い手有利の転職市場とはいえそれは若手にとっての話であり現実問題は思うようには行かないわけです。
このあたりのキャリア形成は非常に迷うものがあります。
そもそも目指すものがあるわけではないけれど、今のところで頑張れるのだろうか?
結局のところ、頑張って駄目ならばしょうがないじゃないか、になるわけですね。
これは、就職氷河期世代にありがちな行動パターンなのかもしれません。
2026年もしばらくは組織的な変化の波が大きい年になるでしょう。
その変化を楽しみつつ、良い方向へと変化を向かわせることができるかどうか。
そこにかかっていそうな気がします。
今年読んだ本
今年もAudibleを中心に色々な本を聞く機会に恵まれました。
これまでもブログで書いてきていますが、特に印象に残っている本をいくつか。

ホワイトカラー消滅 私たちは働き方をどう変えるべきか
今後の少子高齢化社会の中、進化速度の早いAIがますます現実のビジネスに入り込んでいく中、どうなっていくのか?の一冊。
特に本書で示されているスマイルカーブに関しては強く頭に残る話だった

GitLabに学ぶ 世界最先端のリモート組織のつくりかた
正直なところ、私はリモートワークは好きではあるけれどリモートが効率が良いといいきれない側面はあると思っています。
なので、どちらが良いとかそういう話ではなくてケースバイケースであろうと。
本書ではどうすればリモートワークで効率的な仕事をすることができるか?が書かれているわけですが、それ以上にハンドブックという形に言語化していくという手法、マインドの点に強く惹かれた。
というのも、組織内の暗黙ルールって多すぎるというのは自社だけだろうか。
そりゃ、効率化もなにもないよな、と。
というわけで、個人的ではあるものの自社のハンドブックを作り始めています。
何かしら実を結ぶことができればとは思う

クルーシャル・カンバセーション −−重要な対話のための説得術
説得力とあるけれど、実のところは自分自身をちゃんとコントロールする。
なんのためかというと、自分自身の本当の目的のため。
まだ読んでいる最中ではあるけれど、本書はこれまでの自分のコミュニケーション能力の低さを思い知らされる一冊。
自分が情けなくなるほどに、良い本だなと思う。
浅慮なところが多いので本書を読んだところでどこまで実践することができるだろうか?は非常に心配ではあるものの、目的を見誤らないように気をつけていきたいところ。
家族に関して
今年は家族での旅行という意味では、帰省を兼ねた山寺観光に行ったくらいであまり大きな旅行をしていませんでした。
それでも、「今まで行ったことがない場所に行こう!」という旗印のもとあちこち顔を出すことは出来たのではないかと。
あいも変わらず末娘が可愛い。
元気に育っていってほしい。
長女が来年高校受験となるので、最近は勉強づくしの毎日を送っている。
良い結果を迎えることができれば何よりだけれど、どんな結果でもこの頑張りはきっといい方向に向かっていってくれると思う。
次男、三男はちょっと不安だ。
特に三男の、非常に怒りやすいというか、感情をコントロールできなくなってしまう点はこれからどうなるのか。
まさにクルーシャルカンバセーション何だと最近よく思う。
来年は三男もなんだかんだ言って6年生。不安は尽きないけれど、向き合っていくしか無い。
その他
昨年は振り返りのトピックとしてスキルアップという項目も掲げていた。
ただ、思い返してみてもスキルアップしているのかが非常に不安である。
結局のところ資格取得勉強なんて進んでいないし、この1年で自分は何か成長することが出来たのだろうか?
なんかひたすらに走っていたように思えるけれど、それで良いんだっけ?
単純に、走ることのほうが行動としては楽で、そちらに逃げていないだろうか。
来年はこのあたりに答えをしっかりと出していく必要がある。