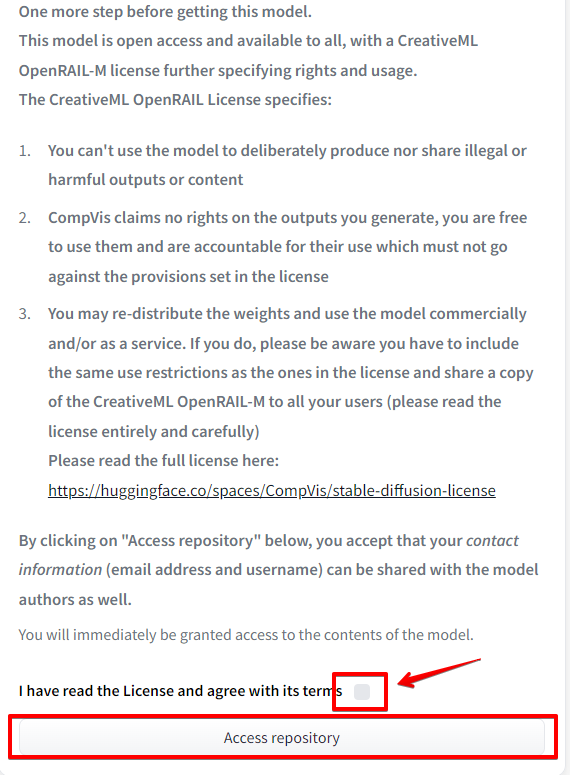
Docker Composeが途中で止まってしまった原因は不明だが、まずは動かしてみたいというところでDevContainer使ってVSCode上のターミナルから試行錯誤してみようとと。
参考はこちら
Stable Diffusionをローカルマシンで実行する(VSCodeとDevcontainerを使用)
https://zenn.dev/hayatok/articles/6141a9a46e4f48
DevContainer準備
VSCodeで適当なフォルダを開き、Dockerfileを作成します
FROM nvcr.io/nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04
ARG DEBIAN_FRONTEND=noninteractive
ENV TZ=Asia/Tokyo
RUN apt-get update && apt-get install -y wget git git-lfs libglib2.0-0 libsm6 libxrender1 libxext-dev
RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && \
sh Miniconda3-latest-Linux-x86_64.sh -b -p /opt/miniconda3 && \
rm -r Miniconda3-latest-Linux-x86_64.sh
ENV PATH /opt/miniconda3/bin:$PATH
RUN git clone https://github.com/CompVis/stable-diffusion && \
cd stable-diffusion && \
conda init bash && \
conda env create -f environment.yaml && \
echo "conda activate ldm" >> ~/.bashrcVSCode のコマンドパレットから「Remote-Containers: Add Development Container Configuration Files…」を選択し、作成したDockerfileを指定します。
devcontainer.jsonが作成されるので、編集します
// For format details, see https://aka.ms/devcontainer.json. For config options, see the README at:
// https://github.com/microsoft/vscode-dev-containers/tree/v0.245.0/containers/docker-existing-dockerfile
{
"name": "Existing Dockerfile",
// Sets the run context to one level up instead of the .devcontainer folder.
"context": "..",
// Update the 'dockerFile' property if you aren't using the standard 'Dockerfile' filename.
"dockerFile": "../Dockerfile",
// 追記ここから。GPU利用可のコンテナ起動オプション
"runArgs":[
"--gpus",
"all"
],
// 追記ここまで。
"customizations": {
"vscode": {
"extensions": [
"ms-python.python"
]
}
}
// Use 'forwardPorts' to make a list of ports inside the container available locally.
// "forwardPorts": [],
// Uncomment the next line to run commands after the container is created - for example installing curl.
// "postCreateCommand": "apt-get update && apt-get install -y curl",
// Uncomment when using a ptrace-based debugger like C++, Go, and Rust
// "runArgs": [ "--cap-add=SYS_PTRACE", "--security-opt", "seccomp=unconfined" ],
// Uncomment to use the Docker CLI from inside the container. See https://aka.ms/vscode-remote/samples/docker-from-docker.
// "mounts": [ "source=/var/run/docker.sock,target=/var/run/docker.sock,type=bind" ],
// Uncomment to connect as a non-root user if you've added one. See https://aka.ms/vscode-remote/containers/non-root.
// "remoteUser": "vscode"
}
コマンドパレットから「Remote-Containers: Rebuild and Reopen in Container」を選択することで、コンテナ内でVSCodeが起動する形となります。
VSCode の左下がこの状態ですね

Modelの配置
前回取得した Hugging Face のモデルを、Stable Diffusionがモデルのデフォルトパスとして指定している”models/ldm/stable-diffusion-v1/model.ckpt”に配備します。
このあたりは、”txt2image.py”を読んでいくとなんのパラメータ指定が出来るのかがわ借ります。
別のパスを指定する場合は —ckpt オプションで指定可能となっています
実行!
参考にさせていただいたページに従って、test.pyを用意し、実行します
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/stable-diffusion# python test.py
Traceback (most recent call last):
File "test.py", line 6, in <module>
pipe = StableDiffusionPipeline.from_pretrained(
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/pipeline_utils.py", line 154, in from_pretrained
cached_folder = snapshot_download(
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/huggingface_hub/utils/_deprecation.py", line 93, in inner_f
return f(*args, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/huggingface_hub/_snapshot_download.py", line 168, in snapshot_download
repo_info = _api.repo_info(
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1454, in repo_info
return self.model_info(
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1276, in model_info
_raise_for_status(r)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 169, in _raise_for_status
raise e
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 131, in _raise_for_status
response.raise_for_status()
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://huggingface.co/api/models/CompVis/stable-diffusion-v1-4/revision/fp16 (Request ID: PQ6M8N2Lators-j6XdN6V)
Access to model CompVis/stable-diffusion-v1-4 is restricted and you are not in the authorized list. Visit https://huggingface.co/CompVis/stable-diffusion-v1-4 to ask for access.
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/stable-diffusion# python test.py
Downloading: 100%|████████████████████████████████████████████████████| 1.34k/1.34k [00:00<00:00, 1.13MB/s]
Downloading: 100%|████████████████████████████████████████████████████| 12.5k/12.5k [00:00<00:00, 11.2MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 342/342 [00:00<00:00, 337kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 543/543 [00:00<00:00, 557kB/s]
Downloading: 100%|████████████████████████████████████████████████████| 4.63k/4.63k [00:00<00:00, 4.02MB/s]
Downloading: 100%|██████████████████████████████████████████████████████| 608M/608M [00:20<00:00, 29.6MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 209/209 [00:00<00:00, 208kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 209/209 [00:00<00:00, 185kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 572/572 [00:00<00:00, 545kB/s]
Downloading: 100%|██████████████████████████████████████████████████████| 246M/246M [00:08<00:00, 29.6MB/s]
Downloading: 100%|███████████████████████████████████████████████████████| 525k/525k [00:00<00:00, 583kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 472/472 [00:00<00:00, 476kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 788/788 [00:00<00:00, 864kB/s]
Downloading: 100%|█████████████████████████████████████████████████████| 1.06M/1.06M [00:01<00:00, 936kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 772/772 [00:00<00:00, 780kB/s]
Downloading: 100%|████████████████████████████████████████████████████| 1.72G/1.72G [00:54<00:00, 31.7MB/s]
Downloading: 100%|█████████████████████████████████████████████████████| 71.2k/71.2k [00:00<00:00, 188kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████| 550/550 [00:00<00:00, 532kB/s]
Downloading: 100%|██████████████████████████████████████████████████████| 167M/167M [00:05<00:00, 28.5MB/s]
0it [00:01, ?it/s]
Traceback (most recent call last):
File "test.py", line 15, in <module>
image = pipe(prompt)["sample"][0]
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py", line 137, in __call__
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/models/unet_2d_condition.py", line 150, in forward
sample, res_samples = downsample_block(
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/models/unet_blocks.py", line 505, in forward
hidden_states = attn(hidden_states, context=encoder_hidden_states)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/models/attention.py", line 168, in forward
x = block(x, context=context)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/models/attention.py", line 196, in forward
x = self.attn1(self.norm1(x)) + x
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/diffusers/models/attention.py", line 245, in forward
sim = torch.einsum("b i d, b j d -> b i j", q, k) * self.scale
RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 4.00 GiB total capacity; 3.13 GiB already allocated; 0 bytes free; 3.13 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFエラーになってしまった。要するにメモリが足りないんだと。
そこでメモリの状態を調べるコマンドを打ってみる
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/stable-diffusion# nvidia-smi
Tue Sep 6 14:52:34 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.65.01 Driver Version: 516.94 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| N/A 56C P3 13W / N/A | 0MiB / 4096MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+むぅ。そもそもいくつあればOKなのかがいまいちわからん。
エラーメッセージに出てきた「PYTORCH_CUDA_ALLOC_CONF」あたりを見ていくと何とかパラメータ指定でうまく行けないかな?という気もするけど、多くの人がStable Diffusionをそのまま使うのではなく、メモリ消費を抑えたバージョンを使っているという事を見聞きしているので、そちらを使うことにする
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2# mkdir basujindal
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2# ls
Dockerfile basujindal stable-diffusion
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2# cd basujindal/
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal# git clone https://github.com/basujindal/stable-diffusion.git適当なフォルダを作って、リポジトリからclone
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal# cd stable-diffusion/
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# python optimizedSD/optimized_txt2img.py --prompt "a photograph of an astronaut riding a horse" --H 512 --W 512 --seed 27 --n_iter 2 --n_samples 10 --ddim_steps 50
Global seed set to 27
Loading model from models/ldm/stable-diffusion-v1/model.ckpt
Traceback (most recent call last):
File "optimizedSD/optimized_txt2img.py", line 184, in <module>
sd = load_model_from_config(f"{ckpt}")
File "optimizedSD/optimized_txt2img.py", line 29, in load_model_from_config
pl_sd = torch.load(ckpt, map_location="cpu")
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/serialization.py", line 699, in load
with _open_file_like(f, 'rb') as opened_file:
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/serialization.py", line 231, in _open_file_like
return _open_file(name_or_buffer, mode)
File "/opt/miniconda3/envs/ldm/lib/python3.8/site-packages/torch/serialization.py", line 212, in __init__
super(_open_file, self).__init__(open(name, mode))
FileNotFoundError: [Errno 2] No such file or directory: 'models/ldm/stable-diffusion-v1/model.ckpt'おっと、モデルを新たに置き直さないと行けない。
サクッとコピーして、再度実行する
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# python optimizedSD/optimized_txt2img.py --prompt "a photograph of an astronaut riding a horse" --H 512 --W 512 --seed 27 --n_iter 2 --n_samples 10 --ddim_steps 50
Global seed set to 27
Loading model from models/ldm/stable-diffusion-v1/model.ckpt
Global Step: 470000
Traceback (most recent call last):
File "optimizedSD/optimized_txt2img.py", line 204, in <module>
model = instantiate_from_config(config.modelUNet)
File "/stable-diffusion/ldm/util.py", line 85, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()))
File "/stable-diffusion/ldm/util.py", line 93, in get_obj_from_str
return getattr(importlib.import_module(module, package=None), cls)
File "/opt/miniconda3/envs/ldm/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 961, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 973, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'optimizedSD'あれ、何だ?optimizedSDがない?
調べてみると、新しくディレクトリ作って作業しているので、PythonのEnvを作り直す必要があるそうだ
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# conda deactivate
(base) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# conda remove -n ldm --all
(base) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# conda env create -f environment.yaml
(base) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# conda activate ldmよし、気を取り直して実行だ
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# python optimizedSD/optimized_txt2img.py --prompt "a photograph of an astronaut riding a horse" --H 512 --W 512 --seed 27 --n_iter 2 --n_samples 10 --ddim_steps 50
Global seed set to 27
Loading model from models/ldm/stable-diffusion-v1/model.ckpt
Global Step: 470000
UNet: Running in eps-prediction mode
CondStage: Running in eps-prediction mode
Downloading: "https://github.com/DagnyT/hardnet/raw/master/pretrained/train_liberty_with_aug/checkpoint_liberty_with_aug.pth" to /root/.cache/torch/hub/checkpoints/checkpoint_liberty_with_aug.pth
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5.10M/5.10M [00:00<00:00, 21.2MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████| 939k/939k [00:01<00:00, 854kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████| 512k/512k [00:00<00:00, 567kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 389/389 [00:00<00:00, 366kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 905/905 [00:00<00:00, 804kB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.31k/4.31k [00:00<00:00, 3.92MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.59G/1.59G [00:59<00:00, 28.5MB/s]
Killedいきなり殺された。。。
stable_diffusion.openvino を WSL2 で実行したけど”Killed” されちゃった人へ
https://zenn.dev/suzuki5080/articles/1438d52377b9df
調べてみると、これも結局はメモリが不足しているために発生しているという可能性が高い。
そして、WSL2に対する割当メモリを変えることで、この問題は解消する可能性が!
[wsl2]
memory=12GB.wslconfigファイルを配備して、再起動。
そして再チャレンジ
(ldm) root@21feb17171f4:/workspaces/StableDiffusion2/basujindal/stable-diffusion# python optimizedSD/optimized_txt2img.py --prompt "a photograph of an astronaut riding a horse" --H 512 --W 512 --seed 27 --n_iter 2 --n_samples 10 --ddim_steps 50
Global seed set to 27
Loading model from models/ldm/stable-diffusion-v1/model.ckpt
Global Step: 470000
UNet: Running in eps-prediction mode
CondStage: Running in eps-prediction mode
FirstStage: Running in eps-prediction mode
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Sampling: 0%| | 0/2 [00:00<?, ?it/sseeds used = [27, 28, 29, 30, 31, 32, 33, 34, 35, 36] | 0/1 [00:00<?, ?it/s]
Data shape for PLMS sampling is [10, 4, 64, 64]
Running PLMS Sampling with 50 timesteps
PLMS Sampler: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [06:46<00:00, 8.13s/it]
torch.Size([10, 4, 64, 64])
saving images 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [06:46<00:00, 8.38s/it]
memory_final = 7.72352
data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [07:04<00:00, 424.21s/it]
Sampling: 50%|██████████████████████████████████████████████████████████ | 1/2 [07:04<07:04, 424.21s/itseeds used = [37, 38, 39, 40, 41, 42, 43, 44, 45, 46] | 0/1 [00:00<?, ?it/s]
Data shape for PLMS sampling is [10, 4, 64, 64]
Running PLMS Sampling with 50 timesteps
PLMS Sampler: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [07:19<00:00, 8.79s/it]
torch.Size([10, 4, 64, 64])
saving images 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [07:19<00:00, 8.62s/it]
memory_final = 6.833664
data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [07:27<00:00, 447.21s/it]
Sampling: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [14:31<00:00, 435.71s/it]
Samples finished in 15.12 minutes and exported to outputs/txt2img-samples/a_photograph_of_an_astronaut_riding_a_horse
Seeds used = 27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46
できた!できたよ、ママン!
ようやく、なんとかStable Diffusionを動かすことが出来る環境を作ることができました。
Pythonに関する知識不足もさることながら、メモリ周りで苦労しますね。
せっかく環境を作ることができたので、もう少し触って遊んでみようと思っています