Vercel社が提供しているv0というサービスを触ってみました
v0はClaudeCodeとはちょっと立ち位置が違う。
プロンプトを用いてアプリケーションを作ってくれるといえばそうなのだが、ClaudeCodeが開発者向きで、生成したコードを見ることが想定されている用に感じる。
それに対してv0は非エンジニアやちょっとしたプロトタイプを作成したい際に、アプリケーションを作ってデプロイまでしてしまう。
ClaudeのArtifactのようにも思えるが、Supabaseなどと連携してVercelの環境で動かすことができてしまう。
今回、こんなプロンプトでクイズアプリケーションを作ってもらった
早押しクイズを提供するサイトを作ってください。
問題出題者はクイズとしてクイズの名前、問題数、カテゴリを登録。
さらに問題とその答えの選択肢、答えと回答時間を設定することが可能です。
クイズをオープンすると、回答者を待つ状態になり、クイズの回答者が参加することが可能になります。
出題者がスタートさせると、回答者の受付は終了し、各回答者のブラウザにクイズの問題と選択肢が提供され、回答を選択することができます。
全員の回答が出揃ったらその問題の答えが出て、正解・不正解と回答の時間によって得点が割り当てられます。
一定時間経つと次の問題が始まります。
最後の問題が終わった段階で、各回答者の得点が表示され、順位が決定します。
結果からすると、思った以上に考えられたものが出来上がったと思う。もちろん、作ってもらうものの参考とするアプリケーション・サービスがそれなりにあるはずで、そういったニーズのものであれば「こういう機能がついている」というセオリーも学びやすいのだろう。
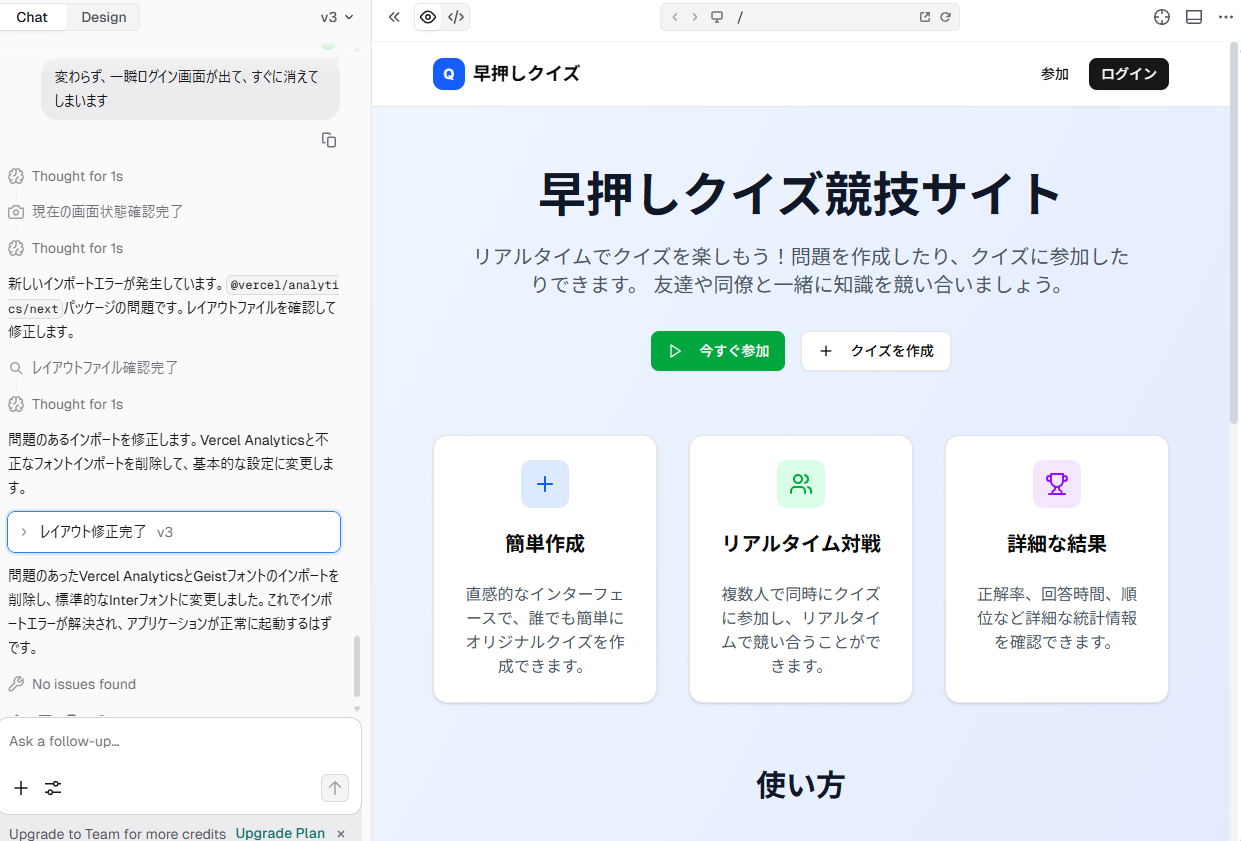
Supabaseと組み合わせることで、ユーザ認証・DBを含めたアプリケーションが出来上がってしまった。
詳しくテストまではできていないのだけど、簡単なものであればそのまま使えるんじゃないかな?と思えてしまった。
技術スタック
v0が生成してくれるコードの技術スタックはVercel提供だけあってNext.jsになる。
Tailwind.cssなどNext.jsを用いる場合に、モダンとされている組み合わせを提供してくれるので、それに関してはこだわりがなければ良さそう。
ちなみに今回作成したUIはpackage.jsonを見るとradix-uiが主に使われているよう。
フロントエンドは不勉強すぎて、radix-uiというものを初めてしった。
Radix-UIは機能のみを提供してスタイルは提供せず自由にカスタマイズ可能というコンセプトのようで、プロジェクトとしては、Radix-UI+TailwindCSSなんですね。
作るものの技術スタックを自分で選びたい。もしくは、すでに決まってしまっている場合には全く使えないものになってしまいそう。
このあたりはプロンプトの指示でどうにでもなるのかもしれない
料金プラン
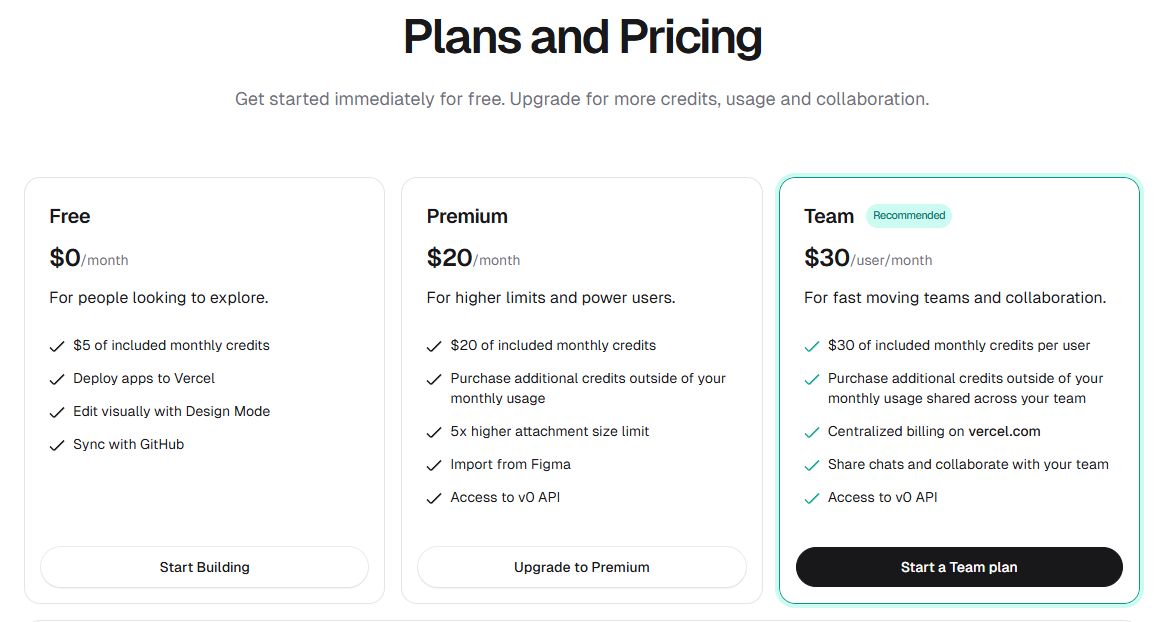
料金プランはFreeの上はPremiumになっていて、最近多くなってきた月$20というところ。
Freeプランだと$5分が毎月割り当てられる
今回、試しに作ってみたクイズアプリケーション。
中身的にはいい感じだが、これを作るのに・・・
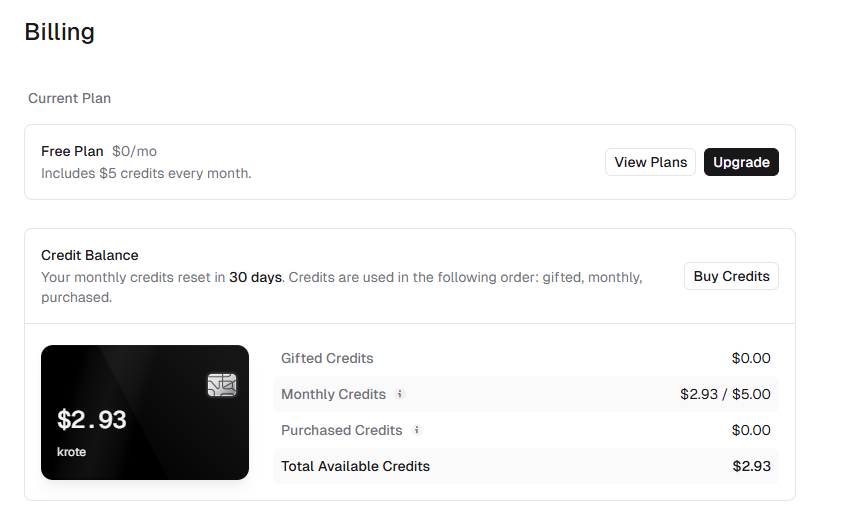
だいたい$3くらいですね。
Claudeへ課金していることを考えると、安く感じてしまうけれど、Supabaseの料金もこれにかかってくるんですよね。
とはいえ、コードはダウンロードして取得したりGithubにそのままコードをPushできるので、Supabaseへの接続部分を変えてしまえば自前で環境は構築できるんじゃないかな・・・。
そのあたりが実は面倒だと、使うのはちょっとためらってしまいそうですね。
感想
どの程度のものが出来上がるかな?と軽い気持ちで試してみたけれど、それなりのものが出来上がってしまってびっくりしている。
恐ろしい子。。。
プロジェクトとしては今回のようにプロンプト初めてもいいし、Githubのリポジトリから持ってくることもできる
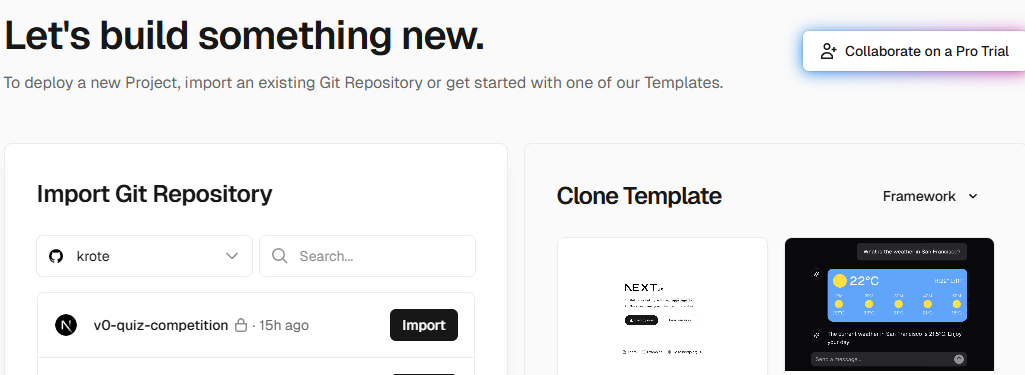
ここで見てみると、TemplateにFrameworkの指定をすることができる。
現時点での選択肢としてはこのようだ
機能やコードに対しての品質的なところまではまだ見切れていないので、CloneしてきてClaudeCodeに評価させるなりしたり、実際にPublishしたりして動かしてみたいですね。
また、Supabaseなど今まで自分が知らなかったサービスやFrameworkを知る機会としてもこういうものが利用できると改めて思いました。
ちょっと楽しくなってきたぞ!