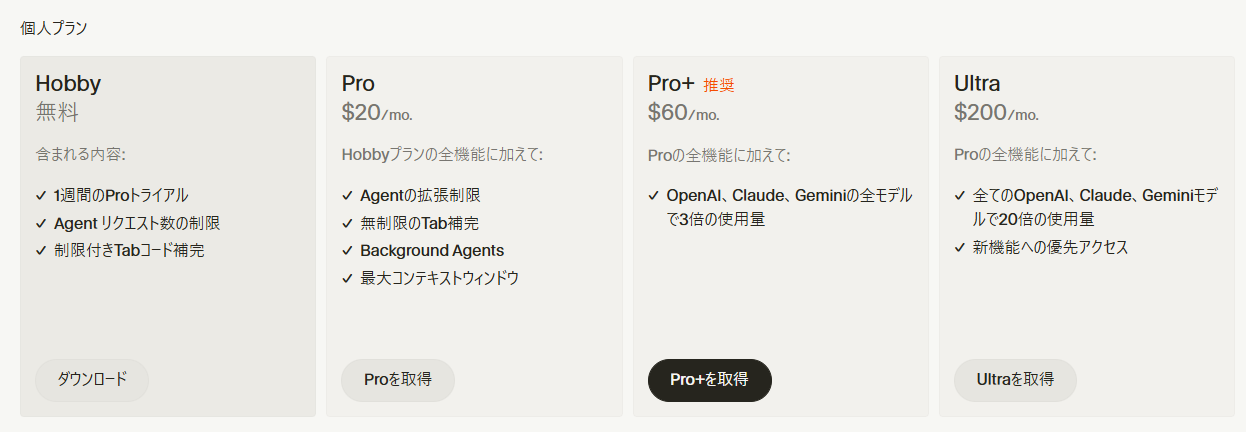
NotebookLMいいですね。
生成されるもののコントロールが難しいところではありますが、それでもいい感じにまとめてくれることが多いような印象です。
最近試してみているのが、読んだ書籍のまとめスライドの作成です。
会社で読んだ本に対して紹介をしようと思ったので作ってみました
Kindleでハイライトする
Kindle本であれば、ハイライトを積極的に利用します。
出来れば、ハイライトにメモを追加するとよいとは思うのですが、私が使っているWhitePaperの反応速度がいまいちなので、メモはあまり使いません。
気になった言葉や残しておきたい言葉を、できるだけ前後の文脈がわかるようにハイライトします。
後から見返したときに、そのものずばりの言葉だけを見ても意味が分からないことが多いので、ハイライトだけでわかるようにしておくといいと思います。
Obsidianにハイライトを取り込んでメモする
ObsidianにはKindle Highlightsという、ハイライトを同期してくれるプラグインがあるので、これでハイライト情報を取り込みます。
ハイライトした文章とそこへのリンクが張られますので、意味が分からない場合は確認をすることが出来ます。
そのうえで、Obsidian上でメモをしていきます。
本を読み終えた後、記憶がある程度残っている状態で反芻するようなイメージですね。
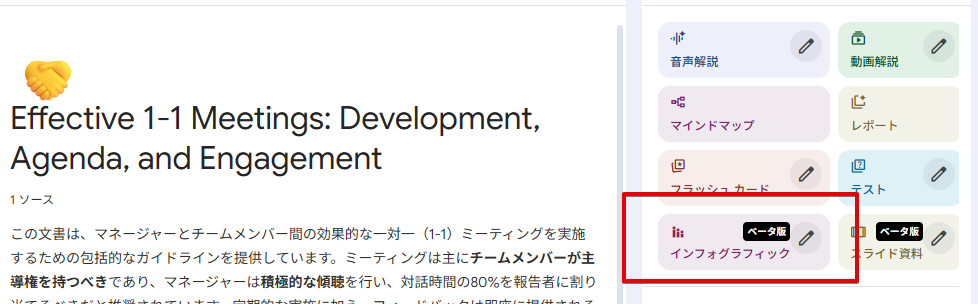
NotebookLMでスライドにする
Obsidianのいいところは、ただのMarkdwonファイルだというところです。
なので、このファイル自体をNotebookLMにソース登録をしてスライド作成を依頼します。
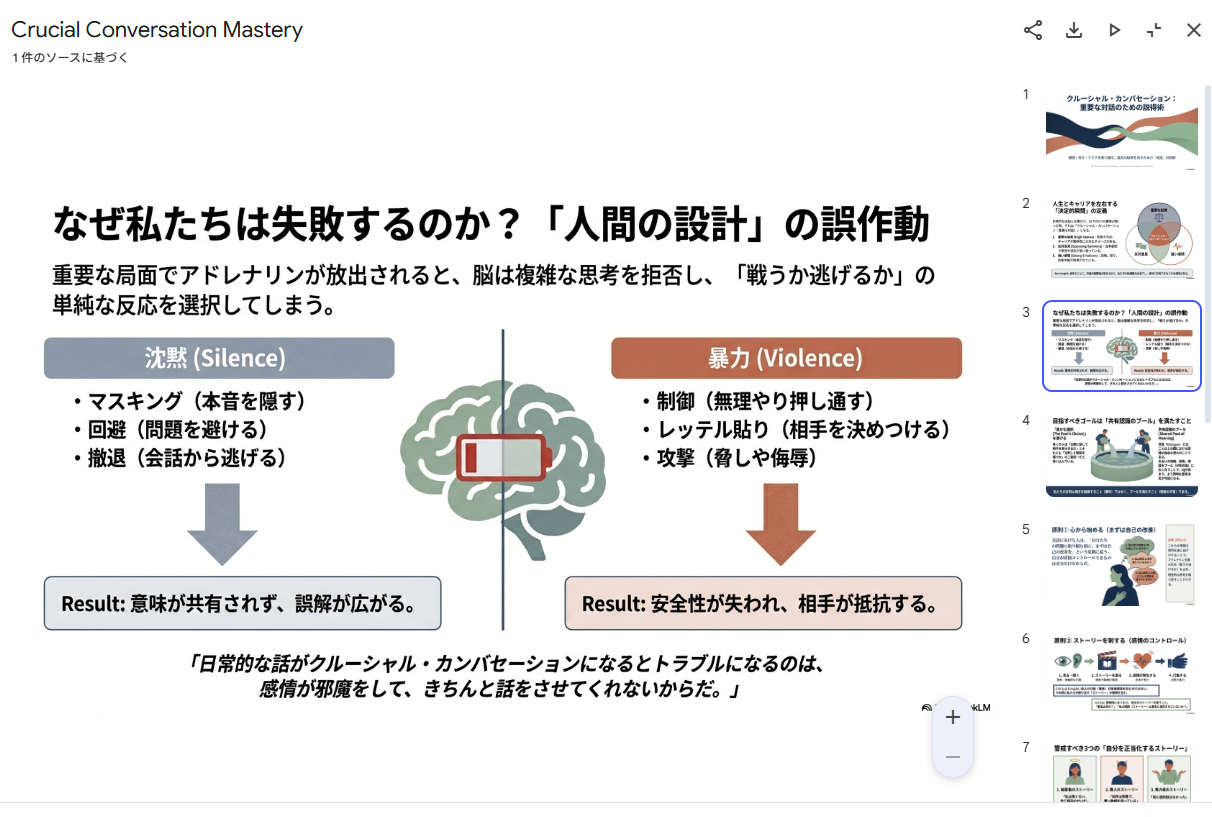
クルーシャルカンバセーションで、自分が興味を持ったところを中心にまとめてくれました。
ここから
今一度これを読み返してみると、なんかすごいまとまっているような気がする。。。
いいではないか。
インフォグラフィックにするのもよいのですが、それなりの分量のある本を対象にしたインフォグラフィックは、かなり当たりはずれある印象です。
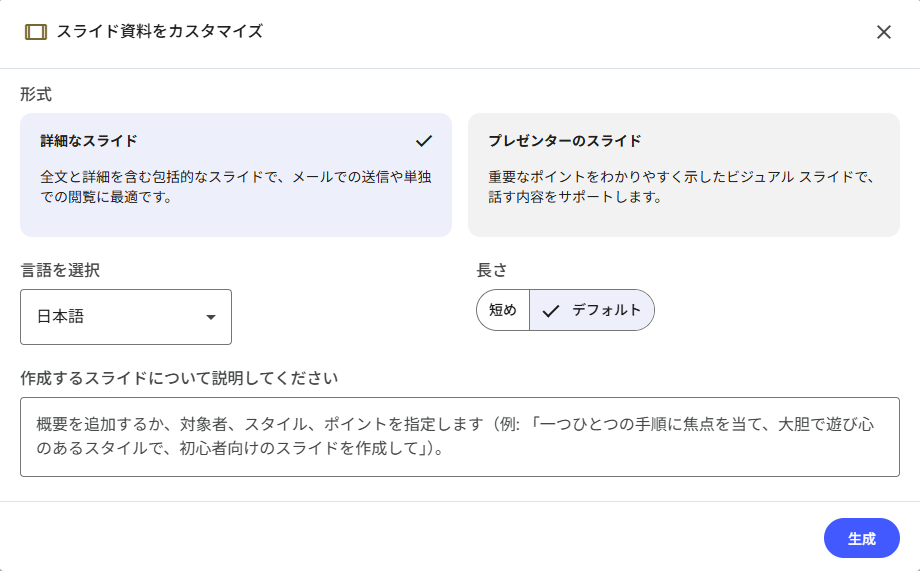
スライドでは、形式や説明文などを指定することが出来ます。
この辺りで、発表想定時間など指示を出すことでもう少しカスタマイズすることが出来そうですね。
面白い!