Electronを利用してのアプリケーション開発で、いくつかの選択肢が存在するけれど、どうせならNext.jsやTypeScriptを使ってみたいと思っていた。
いくつか探したところ、ちょうどいいサンプルがあったのでそれをベースにアプリを作ることにする
Electron with Typescript application example
https://github.com/vercel/next.js/tree/canary/examples/with-electron-typescript
利用の方法はReadmeにかかれているが、下記のような形(プロジェクト名をelectron-exampleにした場合
npx, yarn , pnpmそれぞれ書かれている
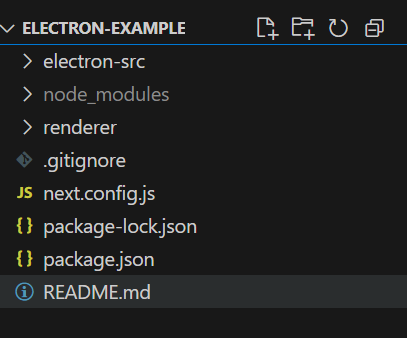
npx create-next-app --example with-electron-typescript electron-exampleyarn create next-app --example with-electron-typescript electron-examplepnpm create next-app --example with-electron-typescript electron-exampleこれで作られるフォルダ構成としてはざっくりこんな感じ
npm run devを実行してみると
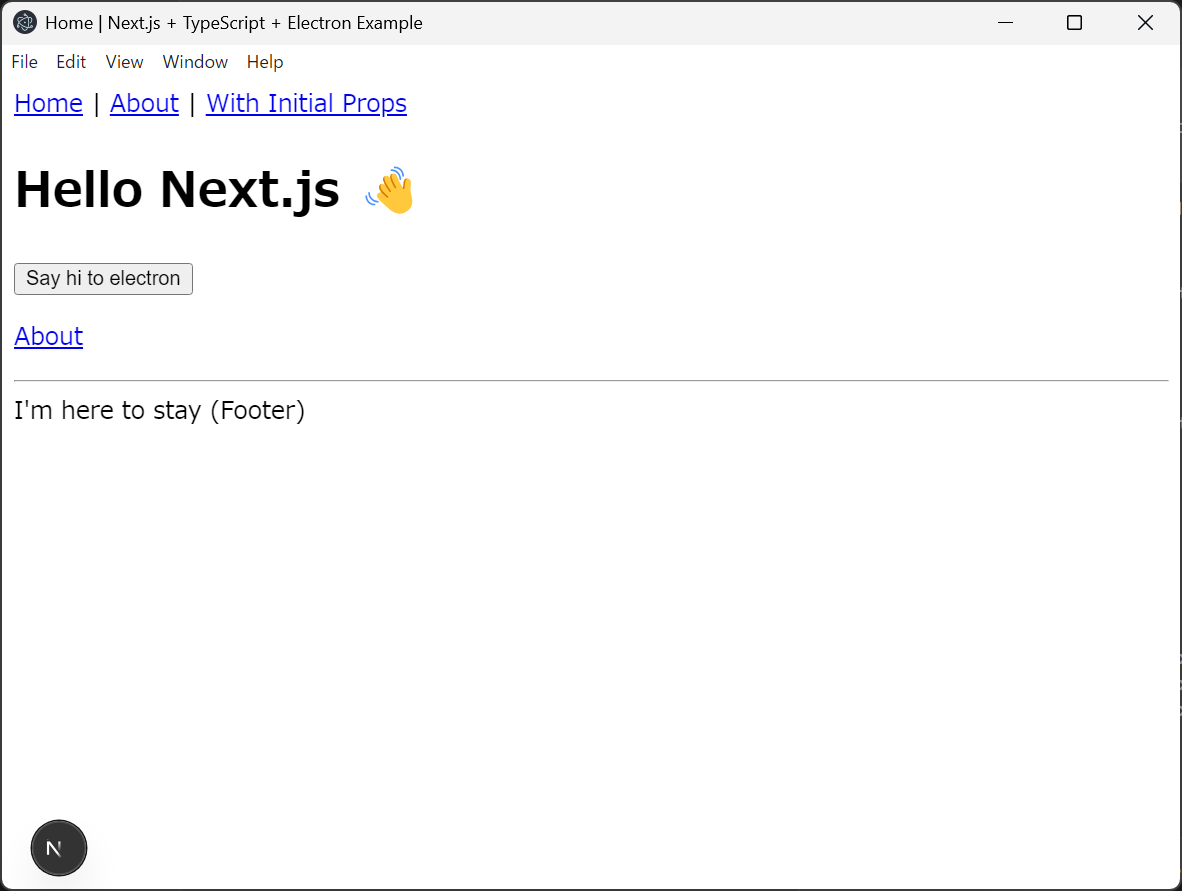
起動した。
ハマったこと
Electron超初心者のわたしがハマったこととしては、、build後のフォルダ構成が下記のように増えたことだった。
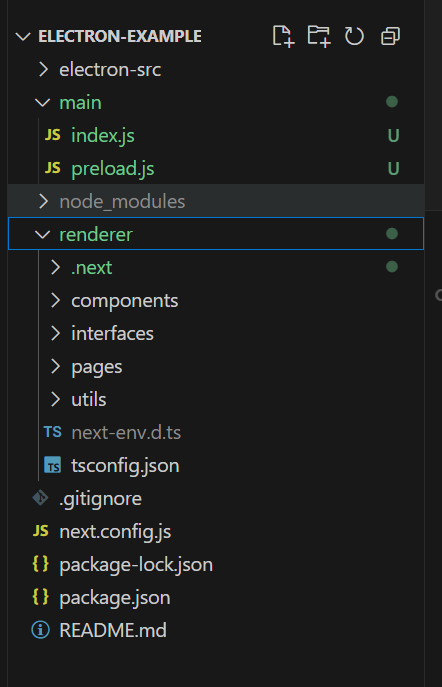
今振り返って考えてみると、これはTypeScriptをコンパイルしてできたファイルになるので、それらは管理対象外なんですよね。
チュートリアルやQiitaを見ながらいじっていたので、main/index.jsやそれをコピーしてmain/main.js等としたりしていたので全然動きませんでした。
それらを考えるとコンパイルによって自動生成されるコードはGithubの対象外にするべきなので、gitignoreは下記を追加しています
/.next/
/out/
main
dist
renderer/.next
renderer/out修正してもビルドしたらもとに戻ったり、思ったものが表示されなかったりと、余計な時間を使ってしまいましたが、ようやくスタートできそう