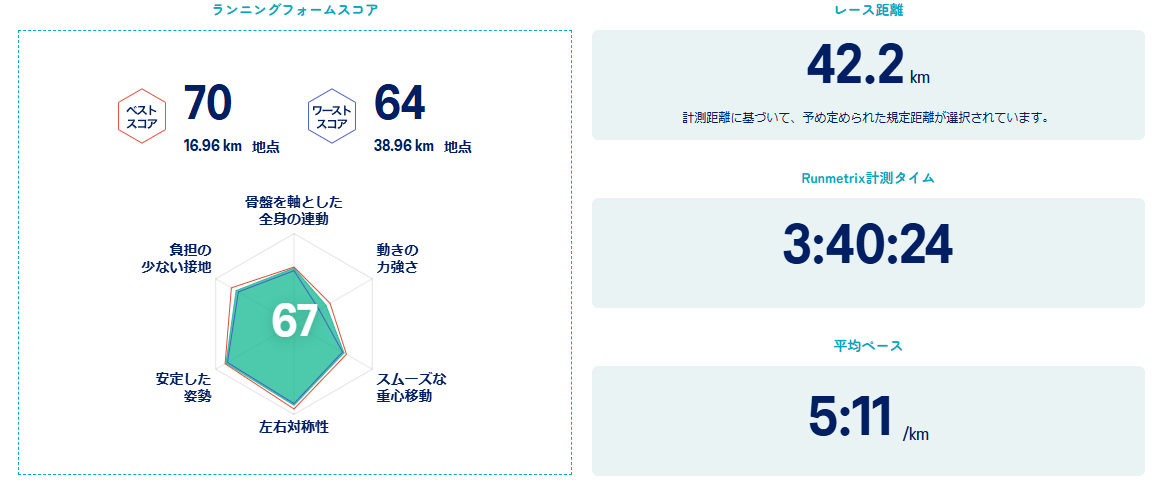
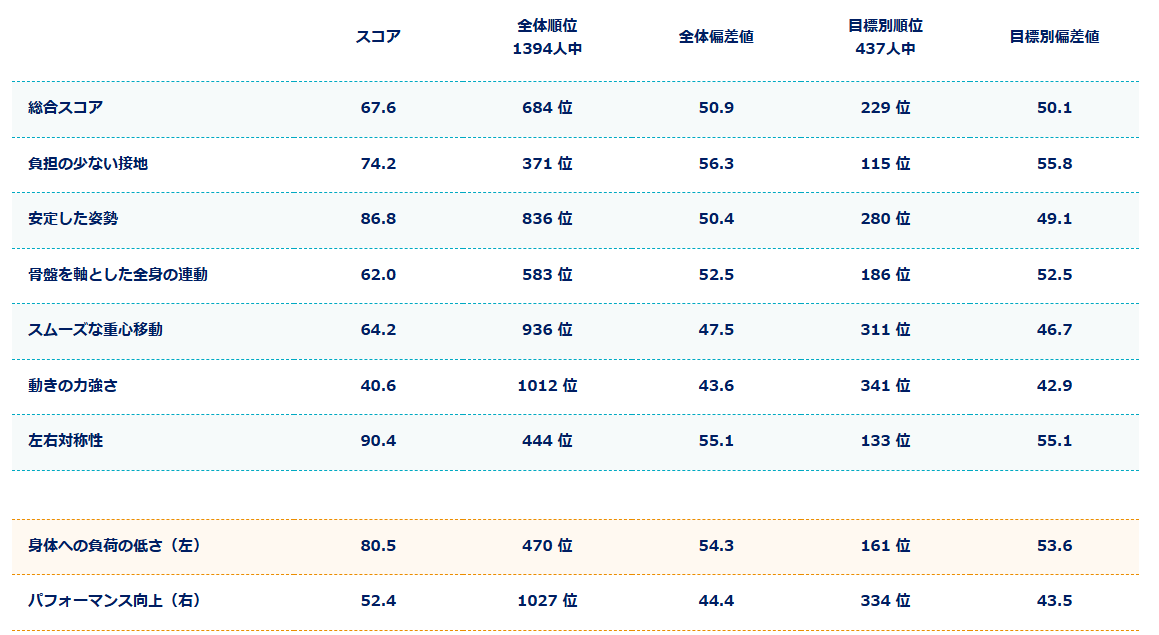
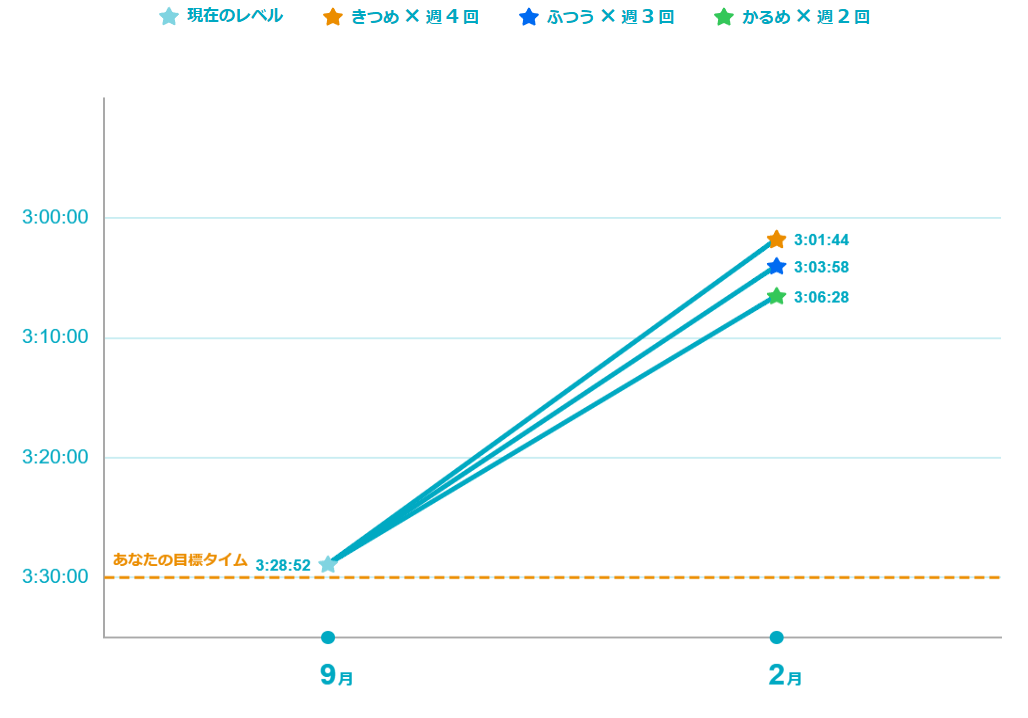
なんだかこの頃、ルパン三世のテーマが個人的にお気に入りになっています。
軽快で、それでいてなんというか哀愁の漂う感じ。
いいですよね。
こんんあものを軽快にピアノで弾くことができればいいのになってことで、スコアバンドを購入しました

当然というかなんというか、私自身はピアノはろくに弾くことができません。
なので、妻にプレゼントと称して渡し、弾いてもらうことに。
ただ、妻もクラシックはそれなりに経験があるもののジャズっぽい曲は勝手が違うようで苦戦しています。
まぁ、それでも素地が違います。練習していれば弾けるようになるでしょう
と、のんびり見ていたら「連弾あるから練習しろ」とオーダーが。。。
私自身、以前にバイオリンを習っていたものの、全然楽譜を読むというところに至らず、何を習っていたんだろう?という感じです。
(当時はなんというか、いわゆるドレミファソラシドで覚えるのではなく元の番号と指の位置で覚えてしまっていたんですよね)
とはいえ、こういう曲をさっそうと弾くことができれば。
1フレーズだけでも弾くことができればかっこいいだろうなぁと。
ちょっとずつ練習していますが、、、まずは楽譜を読んでピアノの位置をさっと関連付けられないとなぁ
先は長そうです