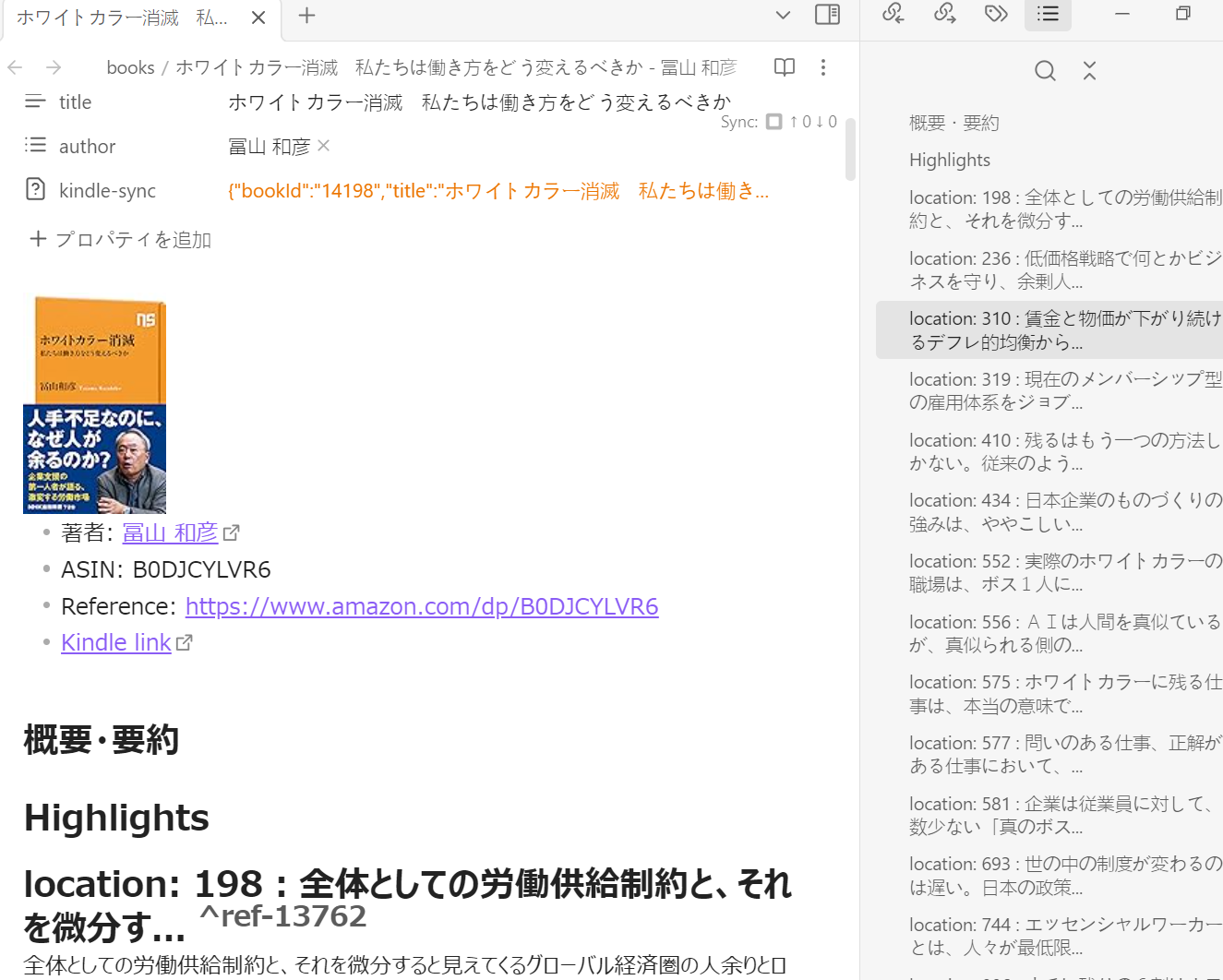
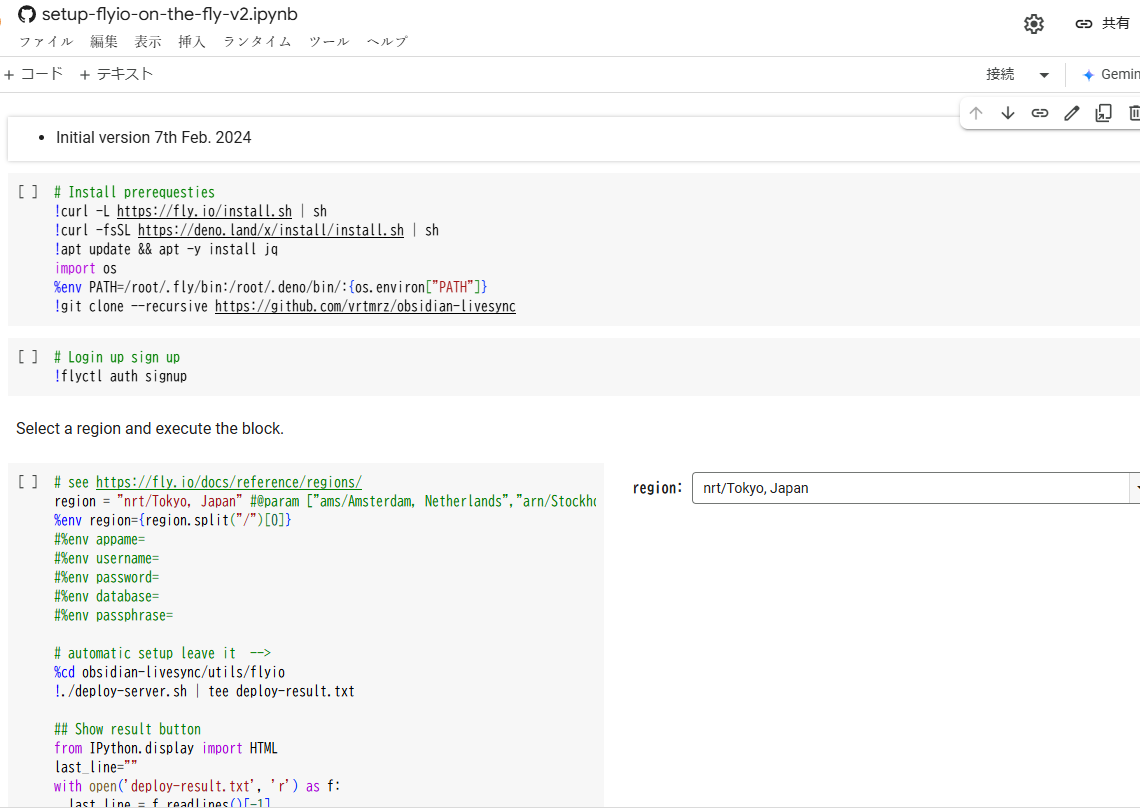
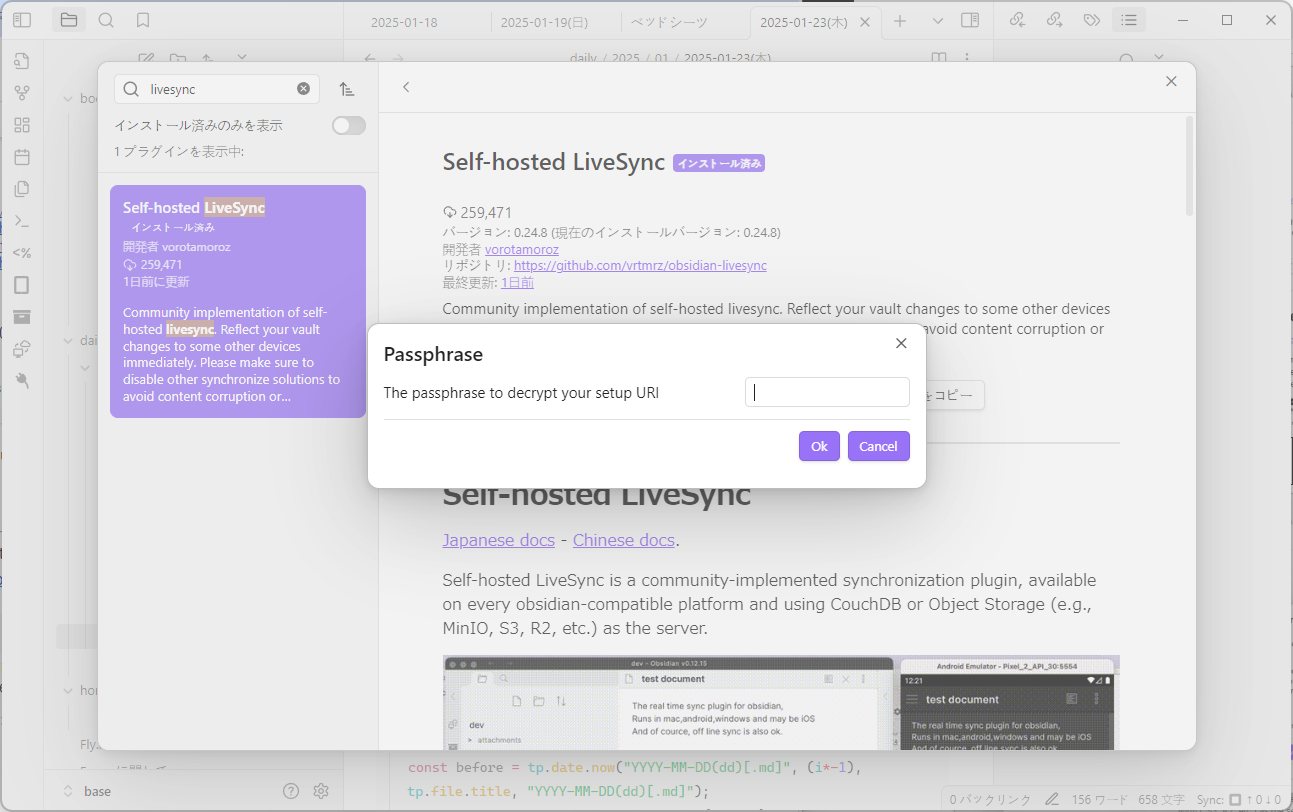
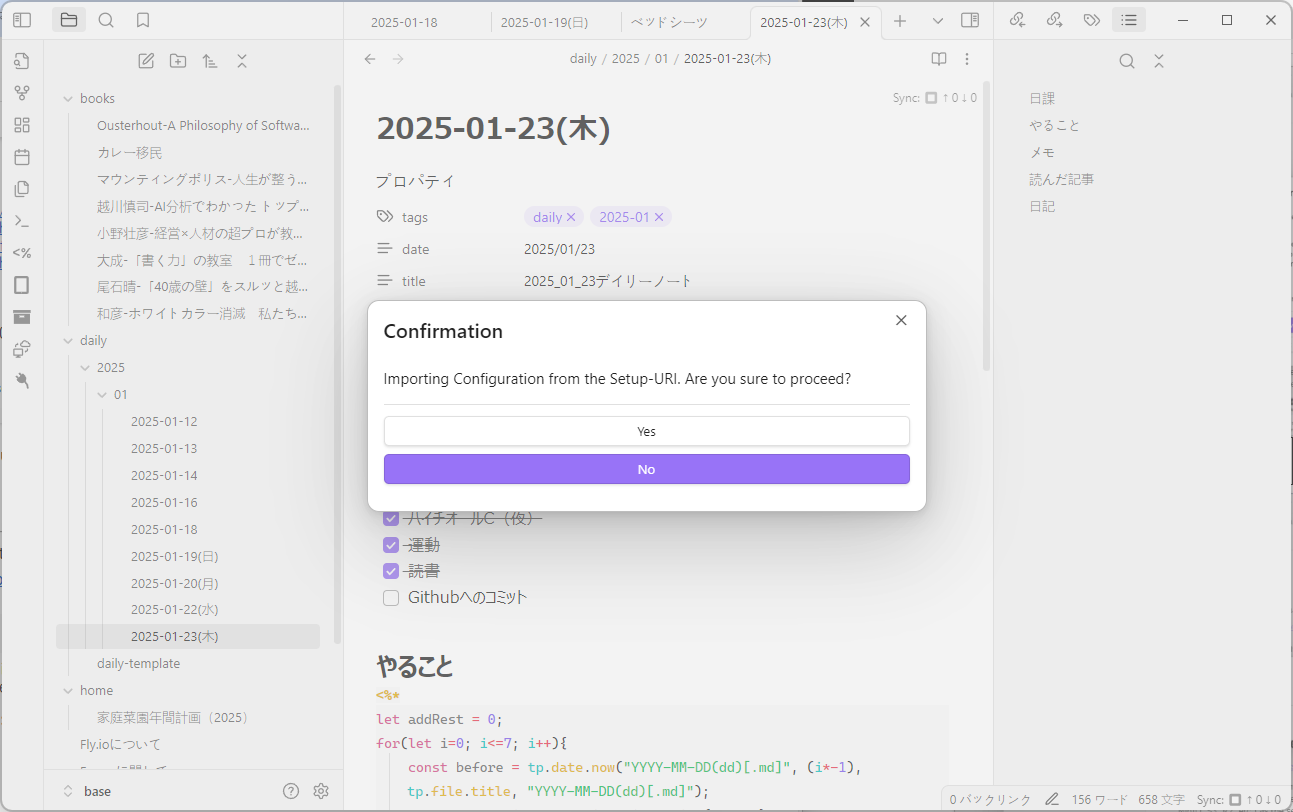
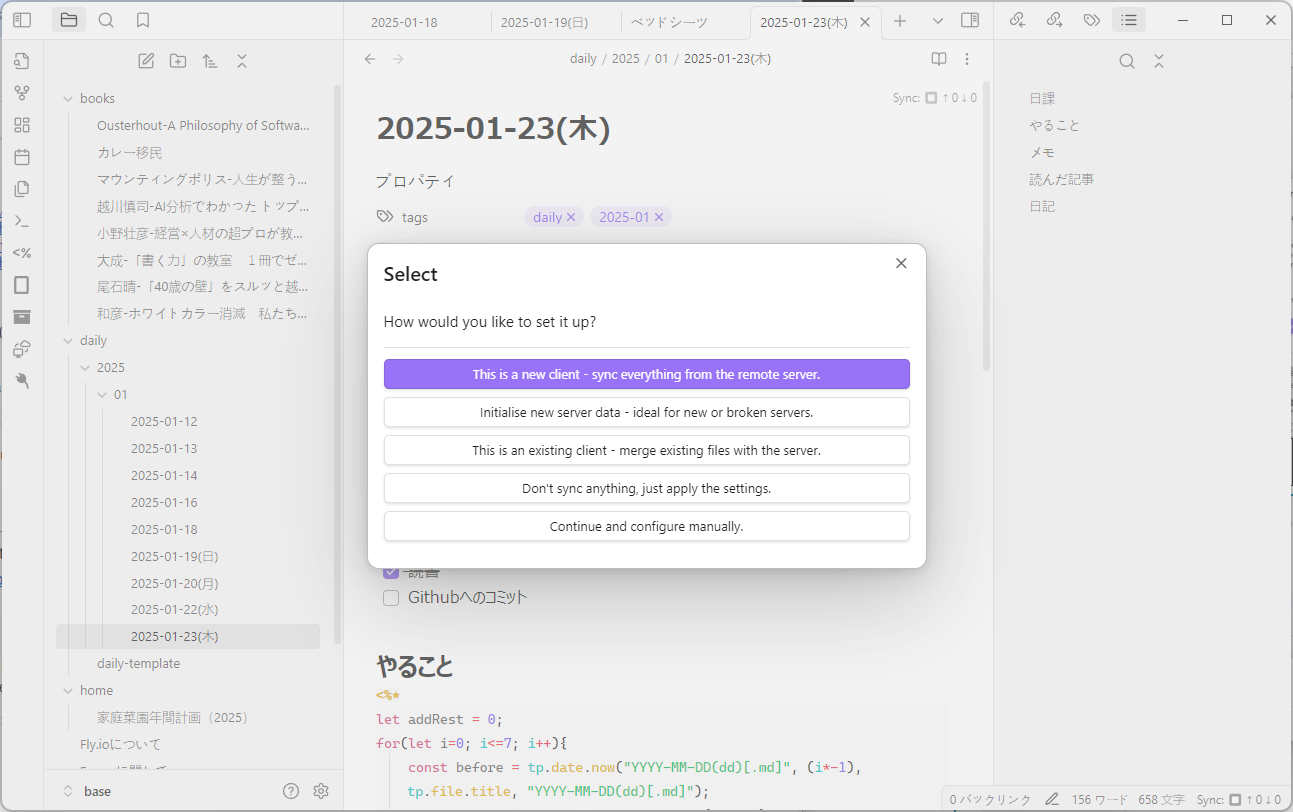
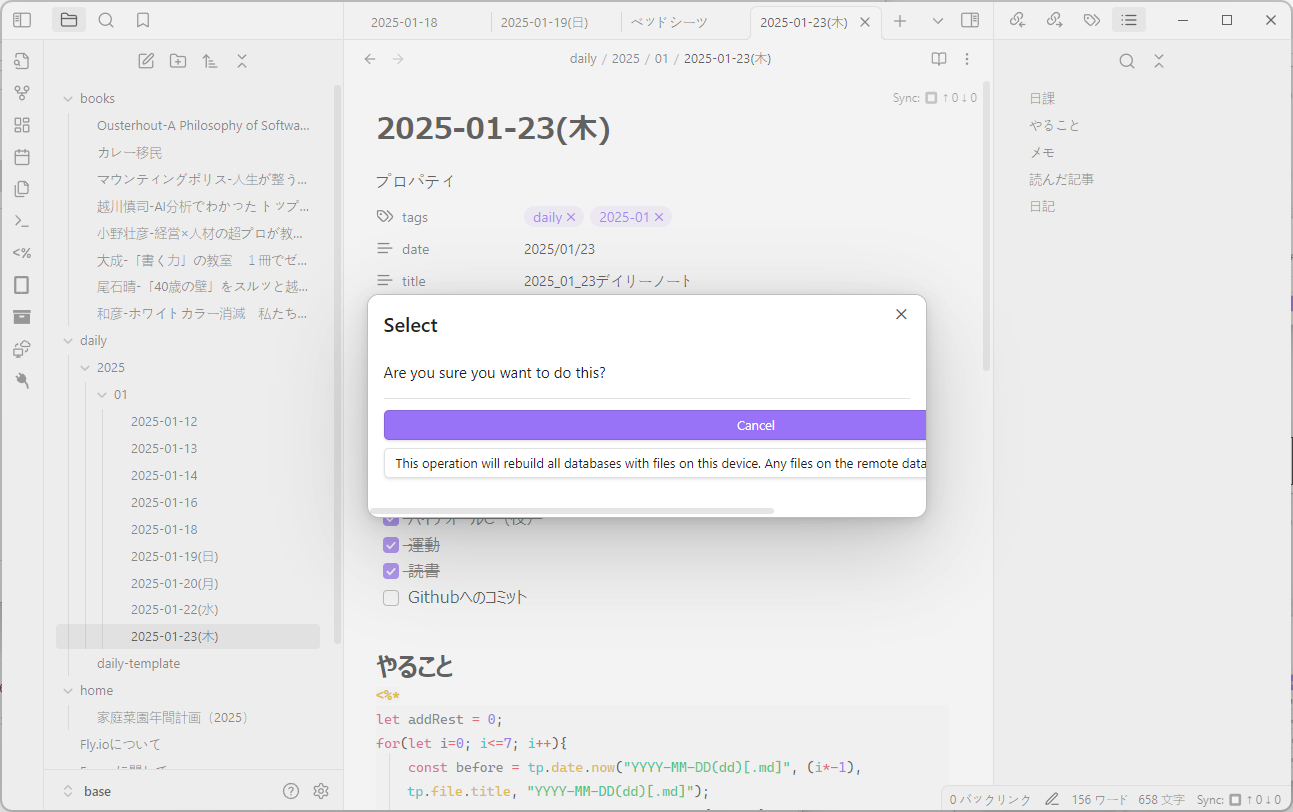
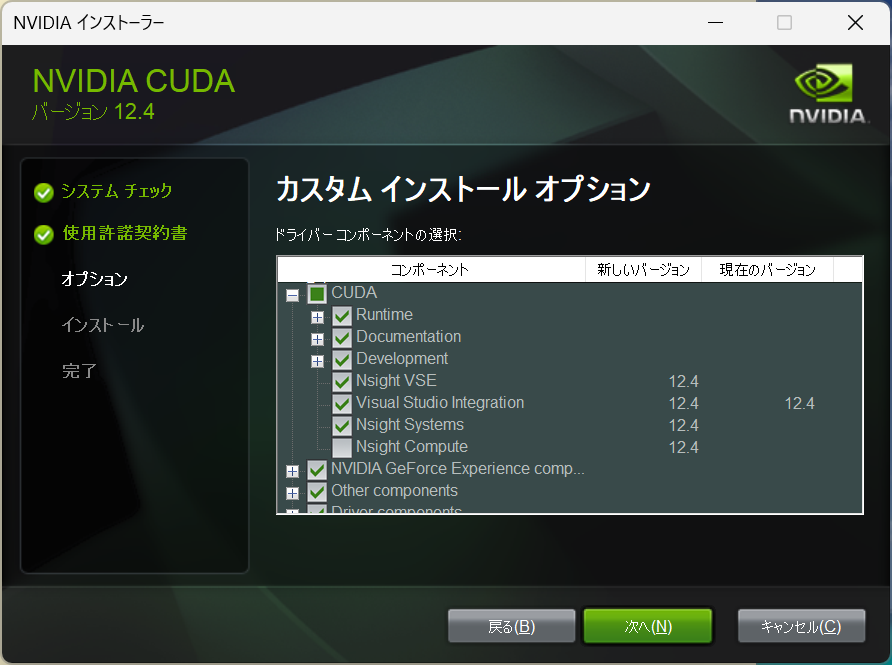
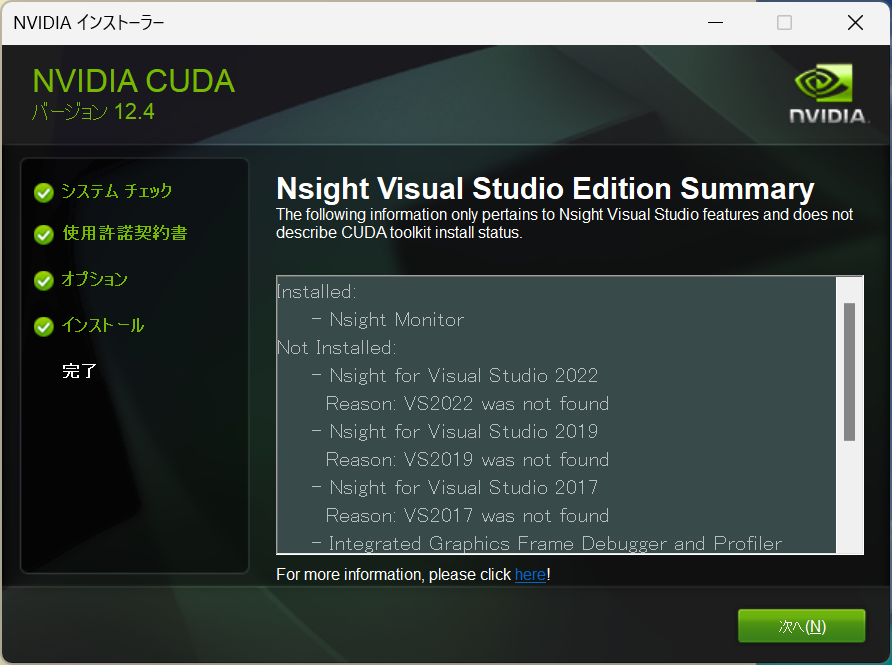
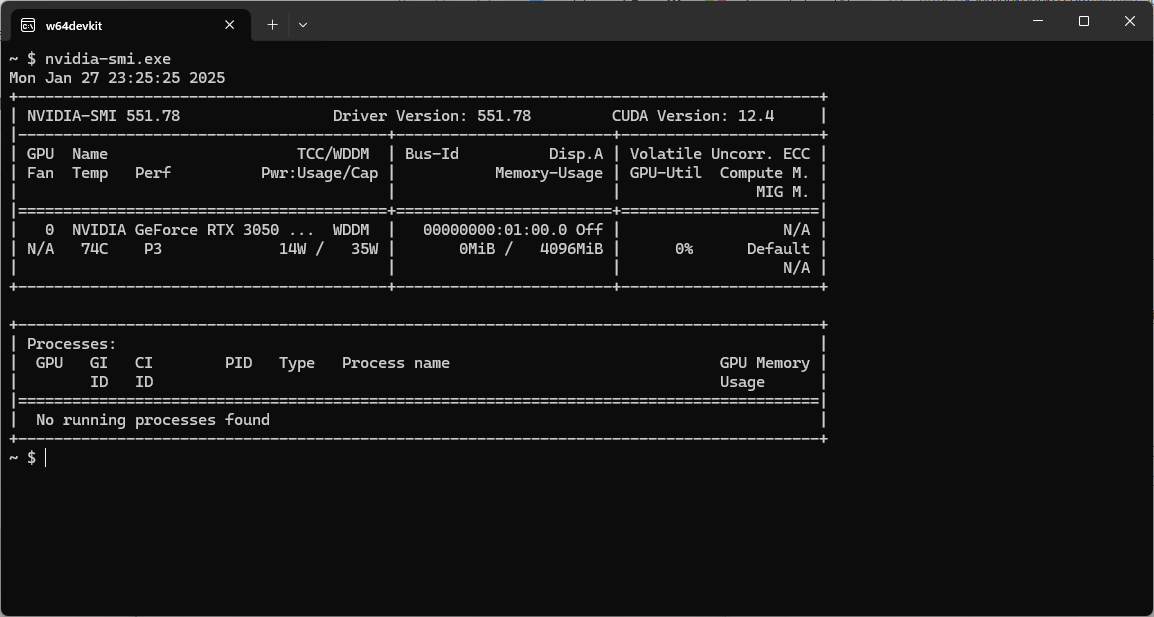
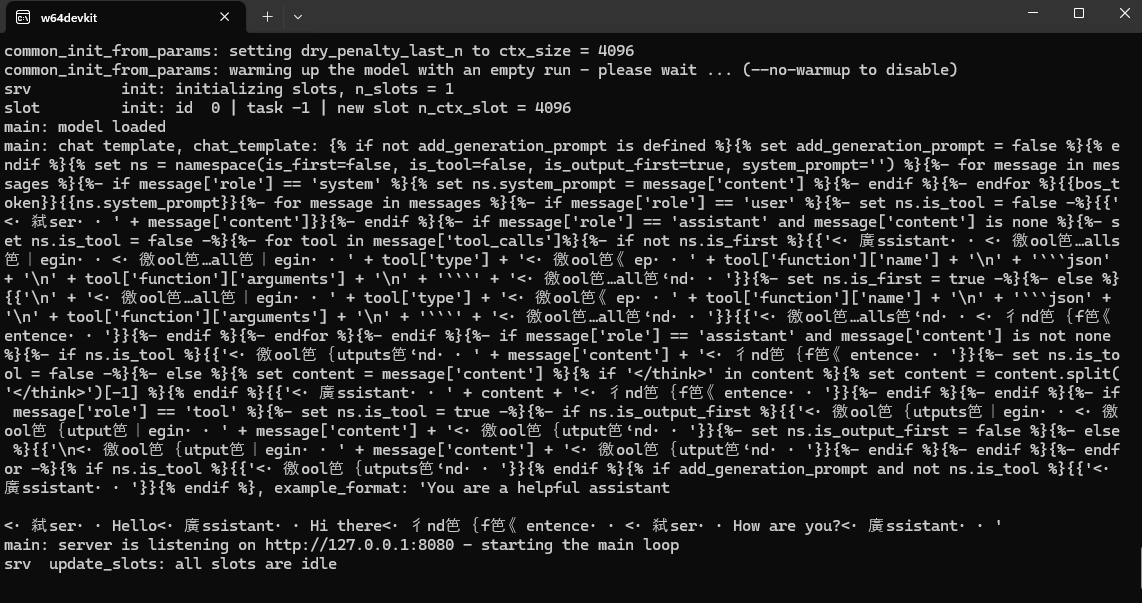
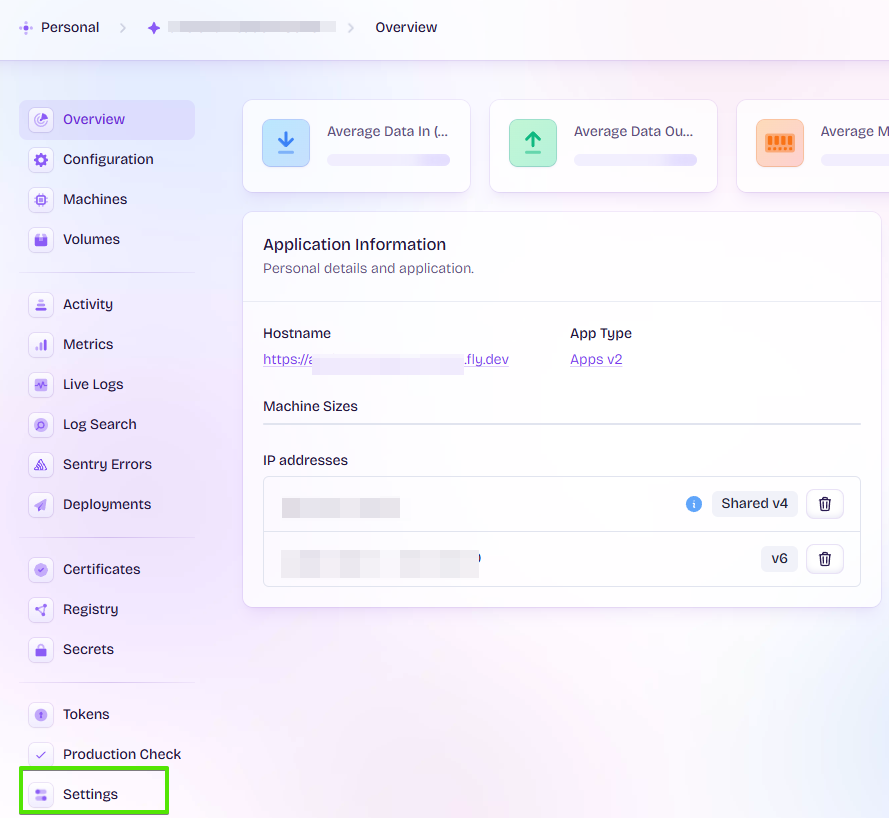
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
ggml_cuda_compute_forward: ADD failed
CUDA error: the provided PTX was compiled with an unsupported toolchain.
current device: 0, in function ggml_cuda_compute_forward at D:\a\llama.cpp\llama.cpp\ggml\src\ggml-cuda\ggml-cuda.cu:2230
err
D:\a\llama.cpp\llama.cpp\ggml\src\ggml-cuda\ggml-cuda.cu:71: CUDA error
sh: ./llama-server.exe: このアプリケーションで、スタック ベースのバッファーのオーバーランが検出されました。このオーバーラン により、悪質なユーザーがこのアプリケーションを制御できるようになる可能性があります。 Error 0xc0000409