試行錯誤を続けているObsidianですが、「後で読む」プラグインを入れてみました。
ちょっといい感じ
そのままの名称「ReadItLater」です。
Pluginをインストールして有効化すると、サイドバーにアイコンが追加されます
URLをクリップボードに入れた状態でアイコンを押すと、対象Webページを読み込んでMarkdownファイルとして保存してくれます

画像も含めてダウンロードして表示してくれるので非常にいい感じです。
デフォルトの設定だと「ReadItLater Inbox」に保存され、画像はassetsフォルダに格納されます。
ただ、読んだあとで不要になった場合にすべての画像が同じassetsフォルダにあるとちょっと削除しづらいな、と考えてプラグインの設定は下記のようにしています。
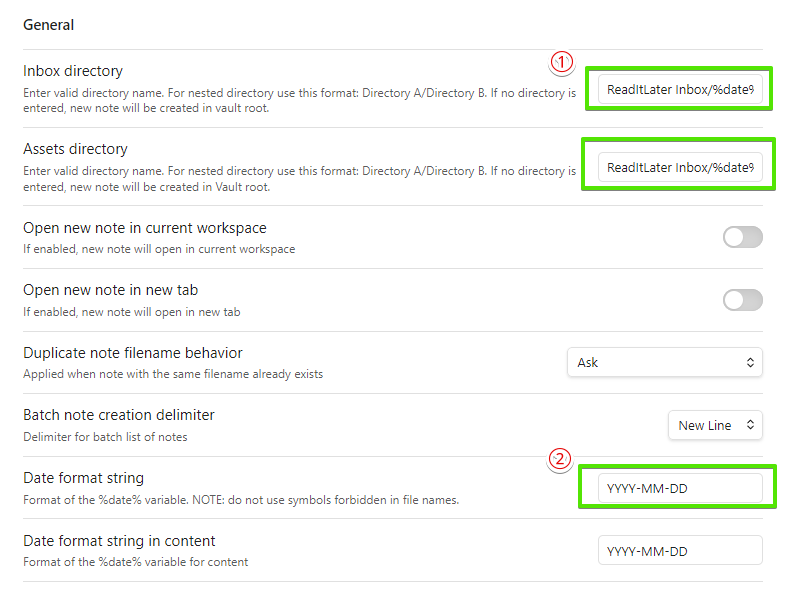
①にある2つの枠で、保存場所に「%date%」フォルダを追加しています。
%date%はデフォルト設定のままだとYYYY-MM-DD HH:MI:SSのように時刻までついてしまうので、②のところは年月日までにしておきます。
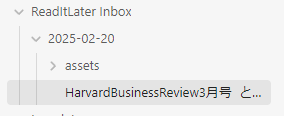
これで、ボタンを押下した日付フォルダにすべてが格納されることになり、不要になった場合は日付フォルダごと消してしまえばいい状態になりました。
少しずつ育てていっている感があっていいです