環境の構築が終わったので、早速、Screenを動かしてみる
準備
まずはScreenを動作させるために必要なライブラリをインストールする
C:\Dev\StreamDiffusion>cd examples
C:\Dev\StreamDiffusion\examples>python -V
Python 3.10.11
C:\Dev\StreamDiffusion\examples>pip install -r screen/requirements.txt
その後、Screenを実行
C:\Dev\StreamDiffusion\examples>py screen\main.py基本的にはこれだけだが、実行ログを見るといくつかのエラーが出ている
Triton?
A matching Triton is not available, some optimizations will not be enabled.
Error caught was: No module named 'triton'単純にみるとtritonモジュールがないぞってこと。
これはWindows環境で起こるものらしい
Windowsの場合はtritonに対応していないため、この表示が出て、かつコード実行に問題がなければ無視しても良い。
https://wikiwiki.jp/sd_toshiaki/No%20module%20named%20%27triton%27
TritonのGithub開発リポジトリを見ても、Linuxのみのサポートのようだ。
Supported Platforms:
https://github.com/openai/triton/?tab=readme-ov-file#compatibility
・Linux
とりあえず、このエラーは無視しても動くようなので気にしないことにする
With TensorRT
これだけでも動くのだがTensorRTを使うとパフォーマンスが向上するとのことで、試してみることに。
C:\Dev\StreamDiffusion\examples>py screen\main.py --acceleration tensorrt実行すると、TensorRTを使う形にコンパイルが走るとともに大量のライブラリが落とされ。。。
OSError: [Errno 28] No space left on device
Model load has failed. Doesn't exist.エラーになった。
これは、ディスクが足りなくなったことを示すエラー。
どんだけ必要なんだ、、、ってことで色々消してやってみたところ
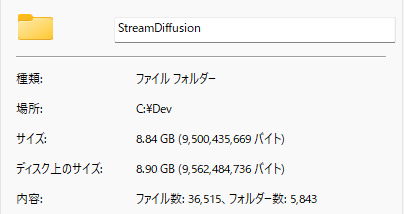
現時点で約9G。
なんとかライブラリも落としきったかな?と思い実行
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 26.00 MiB. GPU 0 has a total capacty of 4.00 GiB of which 0 bytes is free. Of the allocated memory 3.35 GiB is allocated by PyTorch, and 144.71 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Model load has failed. Doesn't exist.GPUのメモリが足りない・・・?
確認してみる
c:\Dev\StreamDiffusion>nvidia-smi
Wed Jan 17 17:13:45 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 522.06 Driver Version: 522.06 CUDA Version: 11.8 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... WDDM | 00000000:01:00.0 Off | N/A |
| N/A 58C P8 9W / N/A | 114MiB / 4096MiB | 22% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 5588 C+G ...ser\Application\brave.exe N/A |
| 0 N/A N/A 7000 C+G ...n64\EpicGamesLauncher.exe N/A |
+-----------------------------------------------------------------------------+今はありそうな気もするけど実行時に足りなくなってしまったということなのかな。
そして結局
Found cached model: engines\KBlueLeaf/kohaku-v2.1--lcm_lora-True--tiny_vae-True--max_batch-2--min_batch-2--mode-img2img\unet.engine.onnx
Generating optimizing model: engines\KBlueLeaf/kohaku-v2.1--lcm_lora-True--tiny_vae-True--max_batch-2--min_batch-2--mode-img2img\unet.engine.opt.onnx
[W] Model does not contain ONNX domain opset information! Using default opset.
UNet: original .. 0 nodes, 0 tensors, 0 inputs, 0 outputs
UNet: cleanup .. 0 nodes, 0 tensors, 0 inputs, 0 outputs
[I] Folding Constants | Pass 1
[W] Model does not contain ONNX domain opset information! Using default opset.
Only support models of onnx opset 7 and above.
Traceback (most recent call last):
File "C:\Dev\StreamDiffusion\examples\screen\..\..\utils\wrapper.py", line 546, in _load_model
compile_unet(
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\streamdiffusion\acceleration\tensorrt\__init__.py", line 76, in compile_unet
builder.build(
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\streamdiffusion\acceleration\tensorrt\builder.py", line 70, in build
optimize_onnx(
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\streamdiffusion\acceleration\tensorrt\utilities.py", line 437, in optimize_onnx
onnx_opt_graph = model_data.optimize(onnx.load(onnx_path))
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\streamdiffusion\acceleration\tensorrt\models.py", line 118, in optimize
opt.fold_constants()
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\streamdiffusion\acceleration\tensorrt\models.py", line 49, in fold_constants
onnx_graph = fold_constants(gs.export_onnx(self.graph), allow_onnxruntime_shape_inference=True)
File "<string>", line 3, in fold_constants
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\polygraphy\backend\base\loader.py", line 40, in __call__
return self.call_impl(*args, **kwargs)
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\polygraphy\util\util.py", line 694, in wrapped
return func(*args, **kwargs)
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\polygraphy\backend\onnx\loader.py", line 424, in call_impl
postfold_num_nodes = onnx_util.get_num_nodes(model)
File "C:\Dev\StreamDiffusion\.venv\lib\site-packages\polygraphy\backend\onnx\util.py", line 41, in get_num_nodes
return _get_num_graph_nodes(model.graph)
AttributeError: 'NoneType' object has no attribute 'graph'
Acceleration has failed. Falling back to normal mode.と、最後に書かれているようにaccelerationに失敗して、通常モードで動くことになってしまっている。
おそらく途中に出てきているONNXが関係しているのかな?
onnx
https://github.com/onnx/onnx
とりあえず
Screenを動かすことはできているけど、私のPCスペックだとスムーズとは言えない。
だからこそTensorRTの恩恵を受けたいところだけどエラーで詰まってしまっているので、このあたりは追々見ていきたいところですね。
こういうものを触っていると、このあたりに関しての知見がいかに自分がないのかがよくわかってくる一方、面白いですね。